 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Apex-Time Network for Cross-Dataset Micro-Expression Recognition
Paper and Code
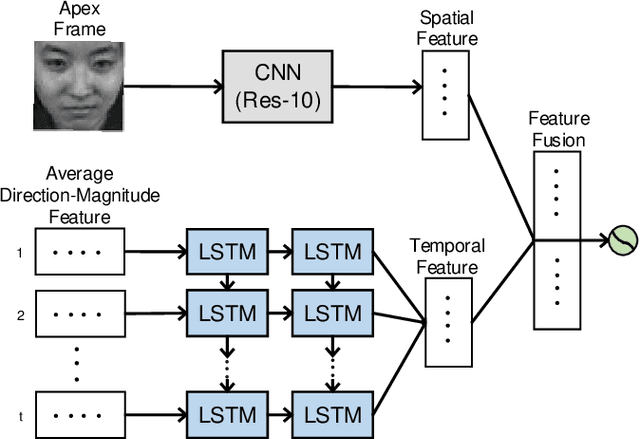
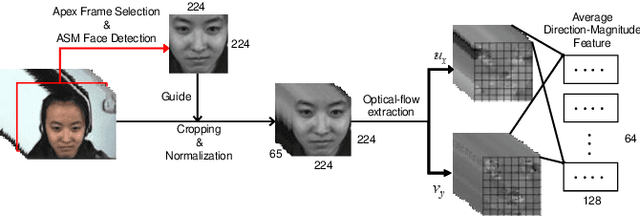
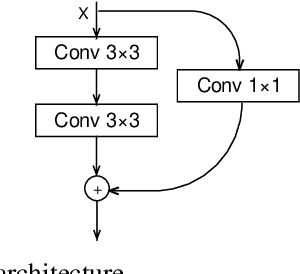
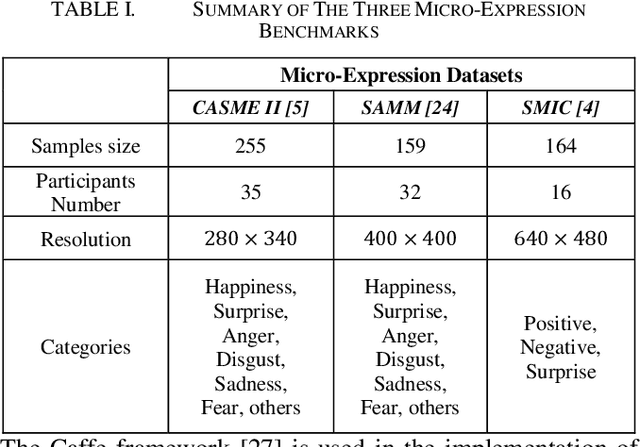
The automatic recognition of micro-expression has been boosted ever since the successful introduction of deep learning approaches. Whilst researchers working on such topics are more and more tending to learn from the nature of micro-expression, the practice of using deep learning techniques has evolved from processing the entire video clip of micro-expression to the recognition on apex frame. Using apex frame is able to get rid of redundant information but the temporal evidence of micro-expression would be thereby left out. In this paper, we propose to do the recognition based on the spatial information from apex frame as well as on the temporal information from respective-adjacent frames. As such, a novel Apex-Time Network (ATNet) is proposed. Through extensive experiments on three benchmarks, we demonstrate the improvement achieved by adding the temporal information learned from adjacent frames around the apex frame. Specially, the model with such temporal information is more robust in cross-dataset validations.