 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Micro-expression in Video Clip with Adaptive Key-frame Mining
Paper and Code
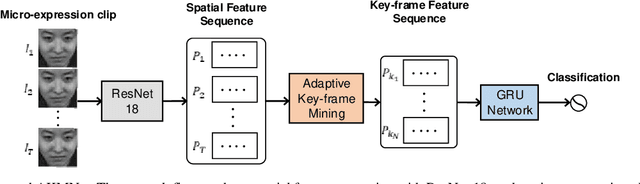
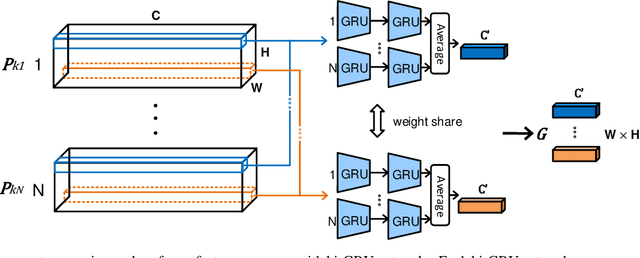
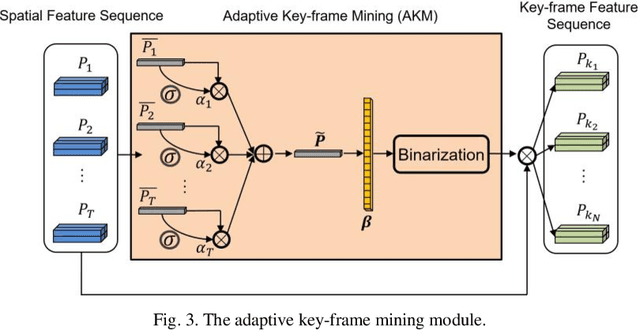
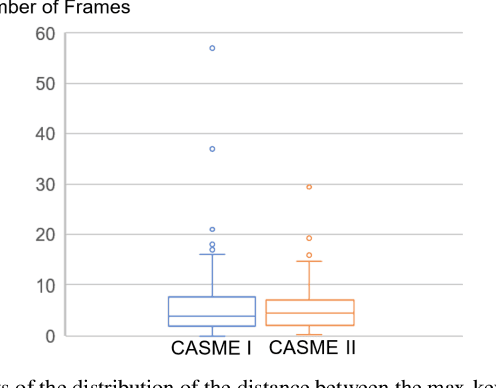
As a spontaneous expression of emotion on face, micro-expression is receiving increasing focus. Whist better recognition accuracy is achieved by various deep learning (DL) techniques, one characteristic of micro-expression has been not fully leveraged. That is, such facial movement is transient and sparsely localized through time. Therefore, the representation learned from a long video clip is usually redundant. On the other hand, methods utilizing the single apex frame require manual annotations and sacrifice the temporal dynamic information. To simultaneously spot and recognize such fleeting facial movement, we propose a novel end-to-end deep learning architecture, referred to as Adaptive Key-frame Mining Network (AKMNet). Operating on the raw video clip of micro-expression, AKMNet is able to learn discriminative spatio-temporal representation by combining the spatial feature of self-exploited local key frames and their global-temporal dynamics. Empirical and theoretical evaluations show advantages of the proposed approach with improved performance comparing with other state-of-the-art methods.