Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Shot Structured Pruning Before Training
Paper and Code
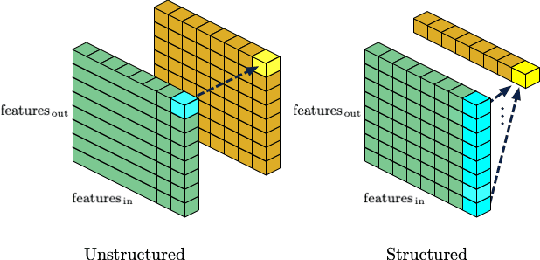
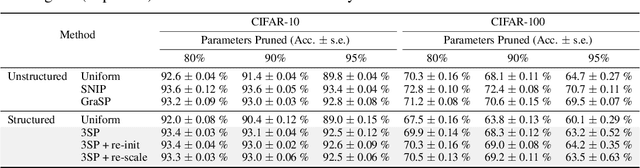
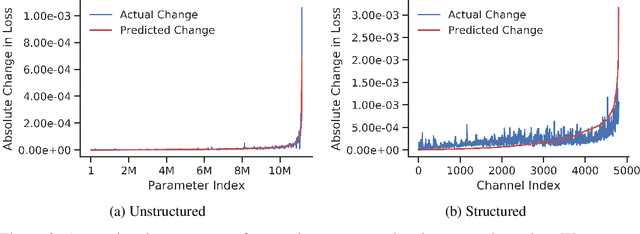

We introduce a method to speed up training by 2x and inference by 3x in deep neural networks using structured pruning applied before training. Unlike previous works on pruning before training which prune individual weights, our work develops a methodology to remove entire channels and hidden units with the explicit aim of speeding up training and inference. We introduce a compute-aware scoring mechanism which enables pruning in units of sensitivity per FLOP removed, allowing even greater speed ups. Our method is fast, easy to implement, and needs just one forward/backward pass on a single batch of data to complete pruning before training begins.
View paper on