 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSailing the Information Ocean with Awareness of Currents: Discovery and Application of Source Dependence
Sep 09, 2009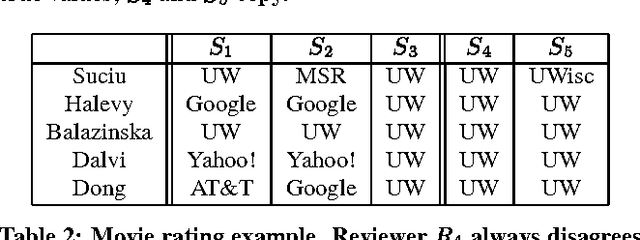


The Web has enabled the availability of a huge amount of useful information, but has also eased the ability to spread false information and rumors across multiple sources, making it hard to distinguish between what is true and what is not. Recent examples include the premature Steve Jobs obituary, the second bankruptcy of United airlines, the creation of Black Holes by the operation of the Large Hadron Collider, etc. Since it is important to permit the expression of dissenting and conflicting opinions, it would be a fallacy to try to ensure that the Web provides only consistent information. However, to help in separating the wheat from the chaff, it is essential to be able to determine dependence between sources. Given the huge number of data sources and the vast volume of conflicting data available on the Web, doing so in a scalable manner is extremely challenging and has not been addressed by existing work yet. In this paper, we present a set of research problems and propose some preliminary solutions on the issues involved in discovering dependence between sources. We also discuss how this knowledge can benefit a variety of technologies, such as data integration and Web 2.0, that help users manage and access the totality of the available information from various sources.