 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlantTracing: Tracing Arabidopsis Thaliana Apex with CenterTrack
May 18, 2024This work applies an encoder-decoder-based machine learning network to detect and track the motion and growth of the flowering stem apex of Arabidopsis Thaliana. Based on the CenterTrack, a machine learning back-end network, we trained a model based on ten time-lapsed labeled videos and tested against three videos.
Interactive $360^{\circ}$ Video Streaming Using FoV-Adaptive Coding with Temporal Prediction
Mar 17, 2024



For $360^{\circ}$ video streaming, FoV-adaptive coding that allocates more bits for the predicted user's field of view (FoV) is an effective way to maximize the rendered video quality under the limited bandwidth. We develop a low-latency FoV-adaptive coding and streaming system for interactive applications that is robust to bandwidth variations and FoV prediction errors. To minimize the end-to-end delay and yet maximize the coding efficiency, we propose a frame-level FoV-adaptive inter-coding structure. In each frame, regions that are in or near the predicted FoV are coded using temporal and spatial prediction, while a small rotating region is coded with spatial prediction only. This rotating intra region periodically refreshes the entire frame, thereby providing robustness to both FoV prediction errors and frame losses due to transmission errors. The system adapts the sizes and rates of different regions for each video segment to maximize the rendered video quality under the predicted bandwidth constraint. Integrating such frame-level FoV adaptation with temporal prediction is challenging due to the temporal variations of the FoV. We propose novel ways for modeling the influence of FoV dynamics on the quality-rate performance of temporal predictive coding.We further develop LSTM-based machine learning models to predict the user's FoV and network bandwidth.The proposed system is compared with three benchmark systems, using real-world network bandwidth traces and FoV traces, and is shown to significantly improve the rendered video quality, while achieving very low end-to-end delay and low frame-freeze probability.
Progressive Frame Patching for FoV-based Point Cloud Video Streaming
Mar 15, 2023Immersive multimedia applications, such as Virtual, Augmented and Mixed Reality, have become more practical with advances in hardware and software for acquiring and rendering 3D media as well as 5G/6G wireless networks. Such applications require the delivery of volumetric video to users with six degrees of freedom (6-DoF) movements. Point Cloud has become a popular volumetric video format due to its flexibility and simplicity. A dense point cloud consumes much higher bandwidth than a 2D/360 degree video frame. User Field of View (FoV) is more dynamic with 6-DoF movement than 3-DoF movement. A user's view quality of a 3D object is affected by points occlusion and distance, which are constantly changing with user and object movements. To save bandwidth, FoV-adaptive streaming predicts user FoV and only downloads the data falling in the predicted FoV, but it is vulnerable to FoV prediction errors, which is significant when a long buffer is used for smoothed streaming. In this work, we propose a multi-round progressive refinement framework for point cloud-based volumetric video streaming. Instead of sequentially downloading frames, we simultaneously downloads/patches multiple frames falling into a sliding time-window, leveraging on the scalability of point-cloud coding. The rate allocation among all tiles of active frames are solved analytically using the heterogeneous tile utility functions calibrated by the predicted user FoV. Multi-frame patching takes advantage of the streaming smoothness resulted from long buffer and the FoV prediction accuracy at short buffer length. We evaluate our solution using simulations driven by real point cloud videos, bandwidth traces and 6-DoF FoV traces of real users. The experiments show that our solution is robust against bandwidth/FoV prediction errors, and can deliver high and smooth quality in the face of bandwidth variations and dynamic user movements.
Learning to Predict on Octree for Scalable Point Cloud Geometry Coding
Sep 06, 2022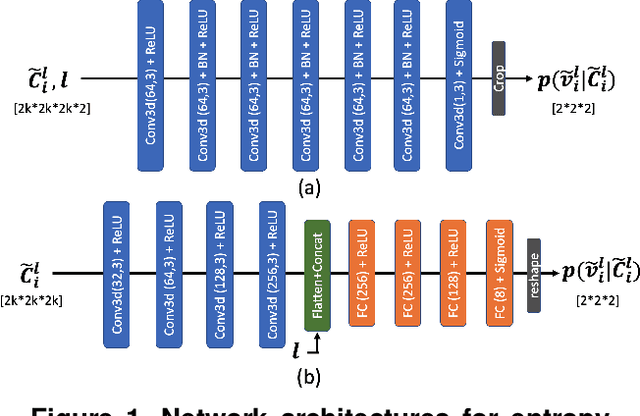
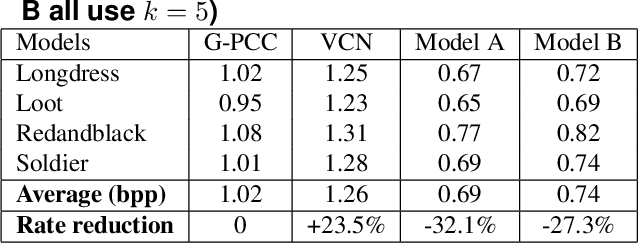
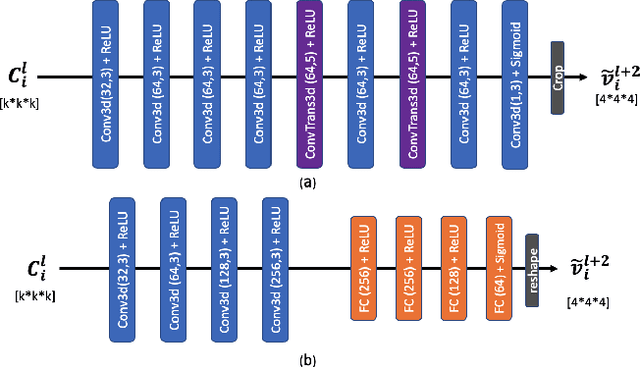
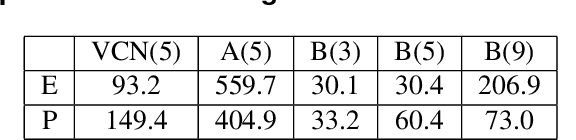
Octree-based point cloud representation and compression have been adopted by the MPEG G-PCC standard. However, it only uses handcrafted methods to predict the probability that a leaf node is non-empty, which is then used for entropy coding. We propose a novel approach for predicting such probabilities for geometry coding, which applies a denoising neural network to a "noisy" context cube that includes both neighboring decoded voxels as well as uncoded voxels. We further propose a convolution-based model to upsample the decoded point cloud at a coarse resolution on the decoder side. Integration of the two approaches significantly improves the rate-distortion performance for geometry coding compared to the original G-PCC standard and other baseline methods for dense point clouds. The proposed octree-based entropy coding approach is naturally scalable, which is desirable for dynamic rate adaptation in point cloud streaming systems.