 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Options Critic
Paper and Code
Jun 11, 2019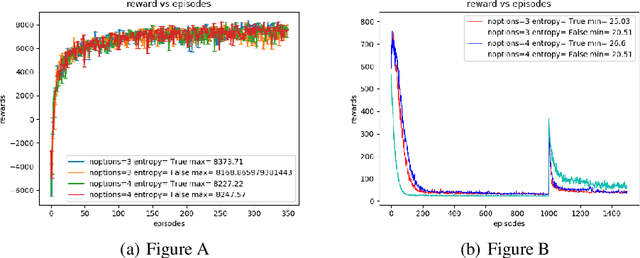
The option-critic architecture (Bacon, Harb, and Precup 2017) and several variants have successfully demonstrated the use of the options framework proposed by Sutton et al (Sutton, Precup, and Singh1999) to scale learning and planning in hierarchical tasks. Although most of these frameworks use entropy as a regularizer to improve exploration, they do not maximize entropy along with returns at every time step. (Haarnoja et al., 2018d) recently introduced an off-policy actor critic algorithm in theSoft Actor Critic paper that maximize returns while maximizing entropy in a constrained manner thus enabling learning of robust options in continuous and discrete action spaces In this paper we adopt the architecture of soft-actor critic to investigate the effect of maximizing entropy of each options and inter-option policy in options framework. We derive the soft options improvement theorem and propose a novel soft-options framework to incorporate maximization of entropy of actions and options in a constrained manner. Our experiments show that the modified options-critic framework generates robust policies which allows fast recovery when environment is subjected to perturbations and outperforms vanilla options-critic framework in most hierarchical tasks