 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed Drafting as a Case Study for First-Principle Interpretability, Memory, and Generalizability in Deep Reinforcement Learning
Nov 17, 2023
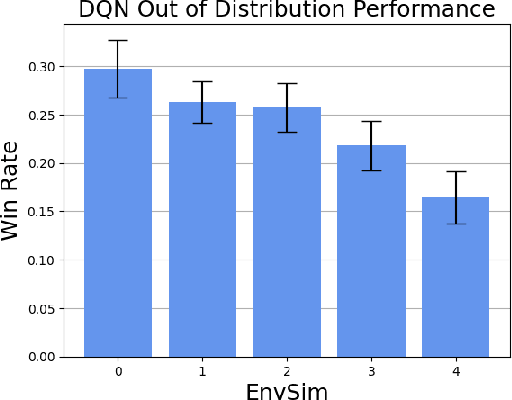
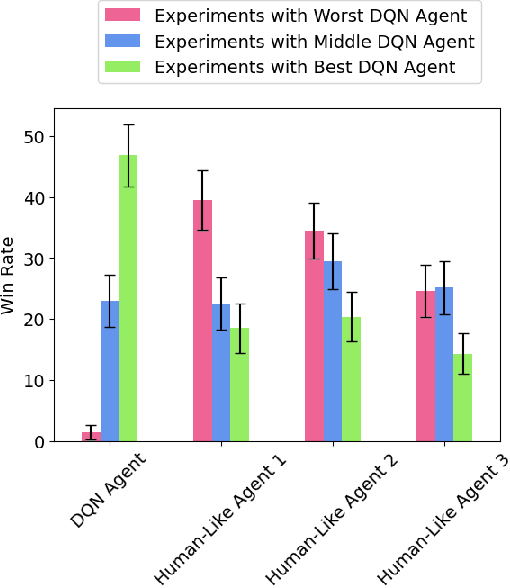
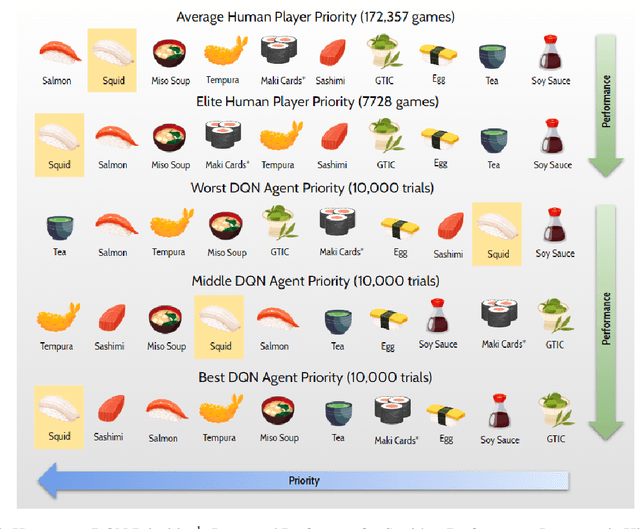
Closed drafting or "pick and pass" is a popular game mechanic where each round players select a card or other playable element from their hand and pass the rest to the next player. In this paper, we establish first-principle methods for studying the interpretability, generalizability, and memory of Deep Q-Network (DQN) models playing closed drafting games. In particular, we use a popular family of closed drafting games called "Sushi Go Party", in which we achieve state-of-the-art performance. We fit decision rules to interpret the decision-making strategy of trained DRL agents by comparing them to the ranking preferences of different types of human players. As Sushi Go Party can be expressed as a set of closely-related games based on the set of cards in play, we quantify the generalizability of DRL models trained on various sets of cards, establishing a method to benchmark agent performance as a function of environment unfamiliarity. Using the explicitly calculable memory of other player's hands in closed drafting games, we create measures of the ability of DRL models to learn memory.