 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMO: Private Regression in Multiple Outcomes
Paper and Code
Mar 07, 2023
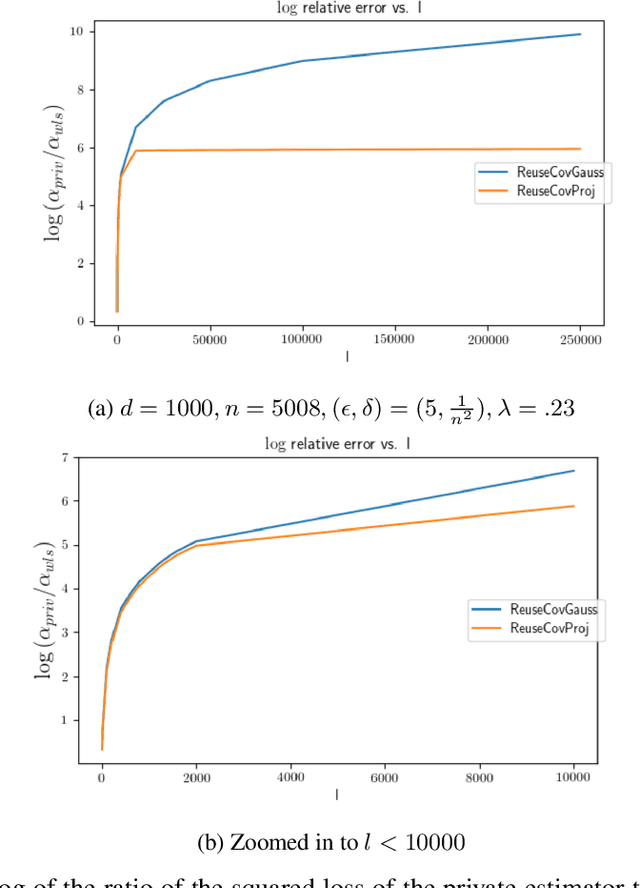
We introduce a new differentially private regression setting we call Private Regression in Multiple Outcomes (PRIMO), inspired the common situation where a data analyst wants to perform a set of $l$ regressions while preserving privacy, where the covariates $X$ are shared across all $l$ regressions, and each regression $i \in [l]$ has a different vector of outcomes $y_i$. While naively applying private linear regression techniques $l$ times leads to a $\sqrt{l}$ multiplicative increase in error over the standard linear regression setting, in Subsection $4.1$ we modify techniques based on sufficient statistics perturbation (SSP) to yield greatly improved dependence on $l$. In Subsection $4.2$ we prove an equivalence to the problem of privately releasing the answers to a special class of low-sensitivity queries we call inner product queries. Via this equivalence, we adapt the geometric projection-based methods from prior work on private query release to the PRIMO setting. Under the assumption the labels $Y$ are public, the projection gives improved results over the Gaussian mechanism when $n < l\sqrt{d}$, with no asymptotic dependence on $l$ in the error. In Subsection $4.3$ we study the complexity of our projection algorithm, and analyze a faster sub-sampling based variant in Subsection $4.4$. Finally in Section $5$ we apply our algorithms to the task of private genomic risk prediction for multiple phenotypes using data from the 1000 Genomes project. We find that for moderately large values of $l$ our techniques drastically improve the accuracy relative to both the naive baseline that uses existing private regression methods and our modified SSP algorithm that doesn't use the projection.