 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocratic Chart: Cooperating Multiple Agents for Robust SVG Chart Understanding
Paper and Code
Apr 14, 2025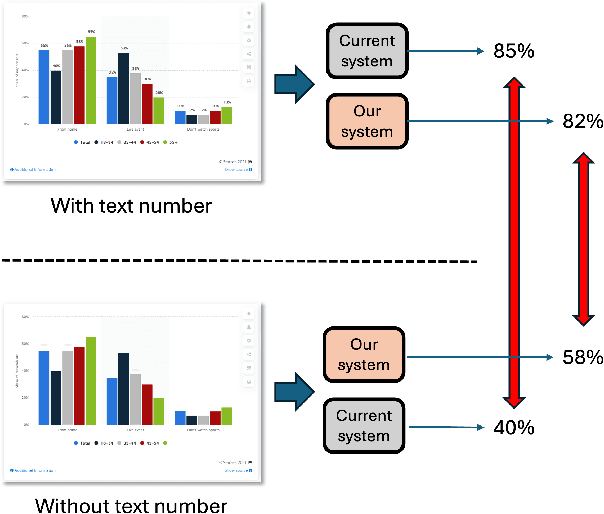



Multimodal Large Language Models (MLLMs) have shown remarkable versatility but face challenges in demonstrating true visual understanding, particularly in chart reasoning tasks. Existing benchmarks like ChartQA reveal significant reliance on text-based shortcuts and probabilistic pattern-matching rather than genuine visual reasoning. To rigorously evaluate visual reasoning, we introduce a more challenging test scenario by removing textual labels and introducing chart perturbations in the ChartQA dataset. Under these conditions, models like GPT-4o and Gemini-2.0 Pro experience up to a 30% performance drop, underscoring their limitations. To address these challenges, we propose Socratic Chart, a new framework that transforms chart images into Scalable Vector Graphics (SVG) representations, enabling MLLMs to integrate textual and visual modalities for enhanced chart understanding. Socratic Chart employs a multi-agent pipeline with specialized agent-generators to extract primitive chart attributes (e.g., bar heights, line coordinates) and an agent-critic to validate results, ensuring high-fidelity symbolic representations. Our framework surpasses state-of-the-art models in accurately capturing chart primitives and improving reasoning performance, establishing a robust pathway for advancing MLLM visual understanding.