 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Student Asynchronous Learning with Multi-Source Consistency for Facial Landmark Detection
Paper and Code
Dec 12, 2020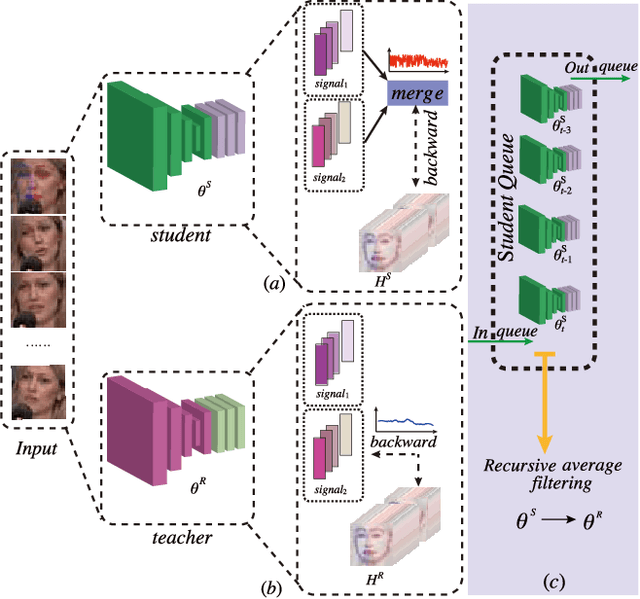

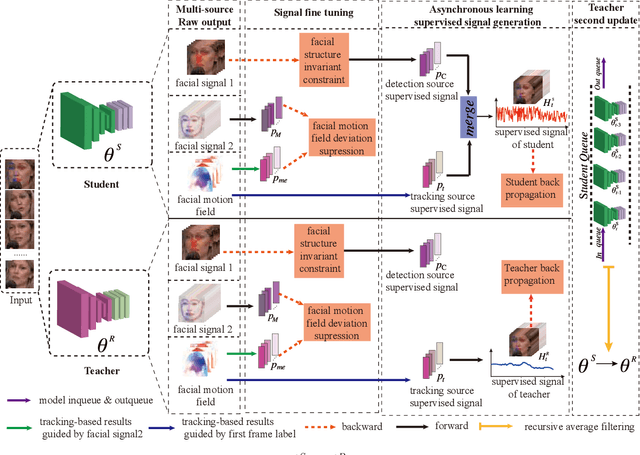

Due to the high annotation cost of large-scale facial landmark detection tasks in videos, a semi-supervised paradigm that uses self-training for mining high-quality pseudo-labels to participate in training has been proposed by researchers. However, self-training based methods often train with a gradually increasing number of samples, whose performances vary a lot depending on the number of pseudo-labeled samples added. In this paper, we propose a teacher-student asynchronous learning~(TSAL) framework based on the multi-source supervision signal consistency criterion, which implicitly mines pseudo-labels through consistency constraints. Specifically, the TSAL framework contains two models with exactly the same structure. The radical student uses multi-source supervision signals from the same task to update parameters, while the calm teacher uses a single-source supervision signal to update parameters. In order to reasonably absorb student's suggestions, teacher's parameters are updated again through recursive average filtering. The experimental results prove that asynchronous-learning framework can effectively filter noise in multi-source supervision signals, thereby mining the pseudo-labels which are more significant for network parameter updating. And extensive experiments on 300W, AFLW, and 300VW benchmarks show that the TSAL framework achieves state-of-the-art performance.