 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
Paper and Code
May 31, 2022

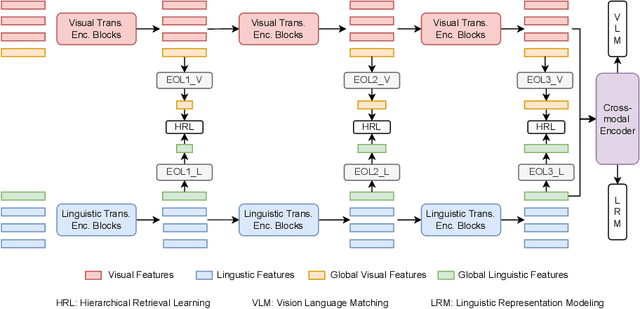
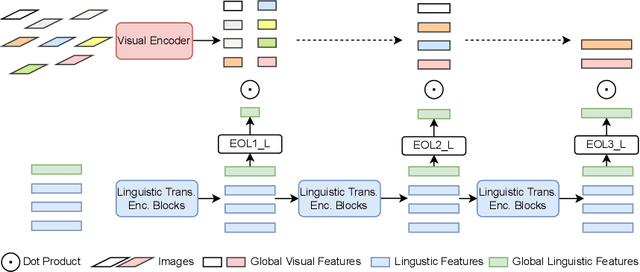
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.