 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Constrained Federated Continual Learning: What Does Matter?
Jan 15, 2025



Federated Continual Learning (FCL) aims to enable sequentially privacy-preserving model training on streams of incoming data that vary in edge devices by preserving previous knowledge while adapting to new data. Current FCL literature focuses on restricted data privacy and access to previously seen data while imposing no constraints on the training overhead. This is unreasonable for FCL applications in real-world scenarios, where edge devices are primarily constrained by resources such as storage, computational budget, and label rate. We revisit this problem with a large-scale benchmark and analyze the performance of state-of-the-art FCL approaches under different resource-constrained settings. Various typical FCL techniques and six datasets in two incremental learning scenarios (Class-IL and Domain-IL) are involved in our experiments. Through extensive experiments amounting to a total of over 1,000+ GPU hours, we find that, under limited resource-constrained settings, existing FCL approaches, with no exception, fail to achieve the expected performance. Our conclusions are consistent in the sensitivity analysis. This suggests that most existing FCL methods are particularly too resource-dependent for real-world deployment. Moreover, we study the performance of typical FCL techniques with resource constraints and shed light on future research directions in FCL.
Better Knowledge Enhancement for Privacy-Preserving Cross-Project Defect Prediction
Dec 23, 2024Cross-Project Defect Prediction (CPDP) poses a non-trivial challenge to construct a reliable defect predictor by leveraging data from other projects, particularly when data owners are concerned about data privacy. In recent years, Federated Learning (FL) has become an emerging paradigm to guarantee privacy information by collaborative training a global model among multiple parties without sharing raw data. While the direct application of FL to the CPDP task offers a promising solution to address privacy concerns, the data heterogeneity arising from proprietary projects across different companies or organizations will bring troubles for model training. In this paper, we study the privacy-preserving cross-project defect prediction with data heterogeneity under the federated learning framework. To address this problem, we propose a novel knowledge enhancement approach named FedDP with two simple but effective solutions: 1. Local Heterogeneity Awareness and 2. Global Knowledge Distillation. Specifically, we employ open-source project data as the distillation dataset and optimize the global model with the heterogeneity-aware local model ensemble via knowledge distillation. Experimental results on 19 projects from two datasets demonstrate that our method significantly outperforms baselines.
Unleashing the Power of Continual Learning on Non-Centralized Devices: A Survey
Dec 18, 2024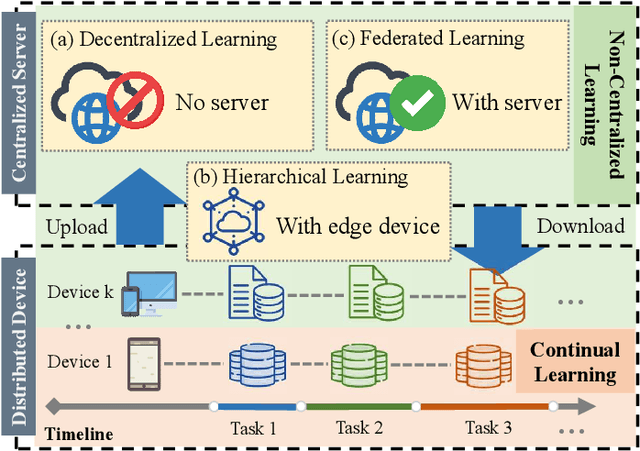
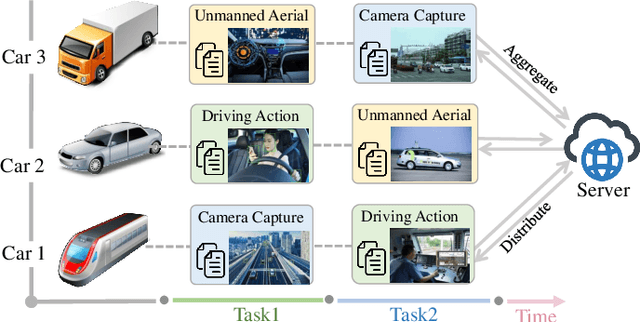
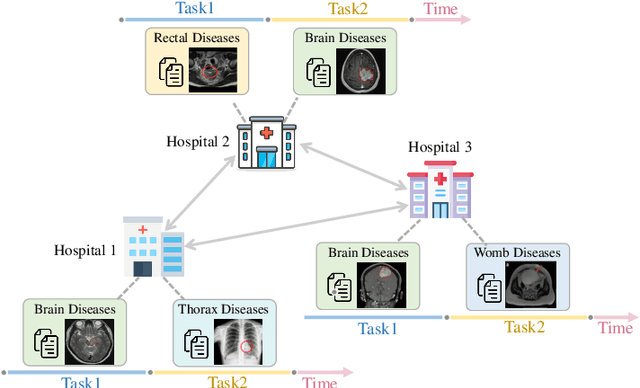
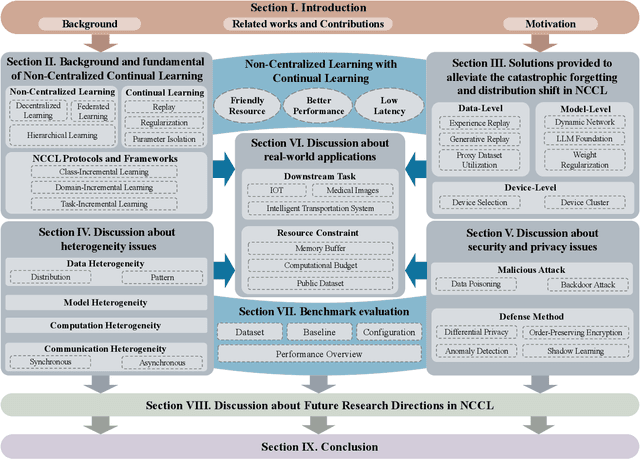
Non-Centralized Continual Learning (NCCL) has become an emerging paradigm for enabling distributed devices such as vehicles and servers to handle streaming data from a joint non-stationary environment. To achieve high reliability and scalability in deploying this paradigm in distributed systems, it is essential to conquer challenges stemming from both spatial and temporal dimensions, manifesting as distribution shifts, catastrophic forgetting, heterogeneity, and privacy issues. This survey focuses on a comprehensive examination of the development of the non-centralized continual learning algorithms and the real-world deployment across distributed devices. We begin with an introduction to the background and fundamentals of non-centralized learning and continual learning. Then, we review existing solutions from three levels to represent how existing techniques alleviate the catastrophic forgetting and distribution shift. Additionally, we delve into the various types of heterogeneity issues, security, and privacy attributes, as well as real-world applications across three prevalent scenarios. Furthermore, we establish a large-scale benchmark to revisit this problem and analyze the performance of the state-of-the-art NCCL approaches. Finally, we discuss the important challenges and future research directions in NCCL.
Rehearsal-Free Continual Federated Learning with Synergistic Regularization
Dec 18, 2024



Continual Federated Learning (CFL) allows distributed devices to collaboratively learn novel concepts from continuously shifting training data while avoiding knowledge forgetting of previously seen tasks. To tackle this challenge, most current CFL approaches rely on extensive rehearsal of previous data. Despite effectiveness, rehearsal comes at a cost to memory, and it may also violate data privacy. Considering these, we seek to apply regularization techniques to CFL by considering their cost-efficient properties that do not require sample caching or rehearsal. Specifically, we first apply traditional regularization techniques to CFL and observe that existing regularization techniques, especially synaptic intelligence, can achieve promising results under homogeneous data distribution but fail when the data is heterogeneous. Based on this observation, we propose a simple yet effective regularization algorithm for CFL named FedSSI, which tailors the synaptic intelligence for the CFL with heterogeneous data settings. FedSSI can not only reduce computational overhead without rehearsal but also address the data heterogeneity issue. Extensive experiments show that FedSSI achieves superior performance compared to state-of-the-art methods.
Residual Network and Embedding Usage: New Tricks of Node Classification with Graph Convolutional Networks
May 21, 2021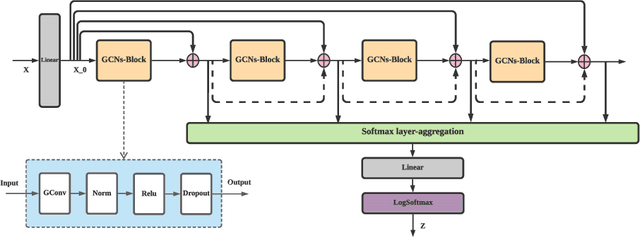
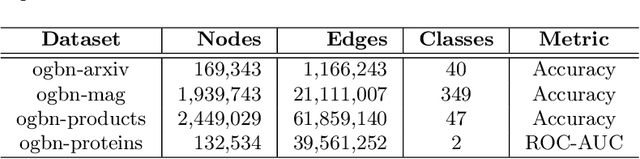
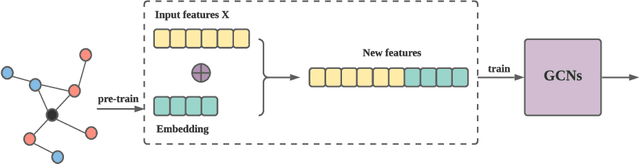
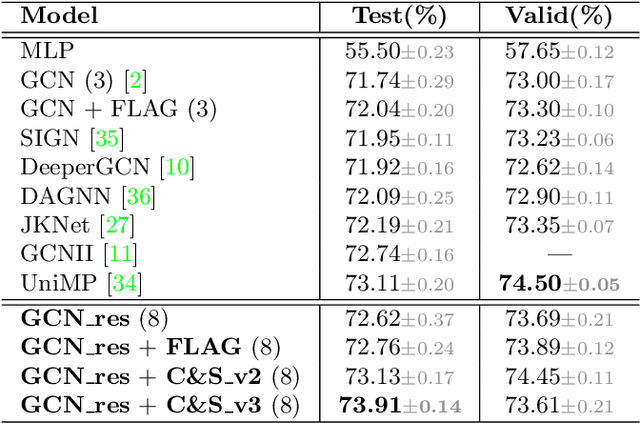
Graph Convolutional Networks (GCNs) and subsequent variants have been proposed to solve tasks on graphs, especially node classification tasks. In the literature, however, most tricks or techniques are either briefly mentioned as implementation details or only visible in source code. In this paper, we first summarize some existing effective tricks used in GCNs mini-batch training. Based on this, two novel tricks named GCN_res Framework and Embedding Usage are proposed by leveraging residual network and pre-trained embedding to improve baseline's test accuracy in different datasets. Experiments on Open Graph Benchmark (OGB) show that, by combining these techniques, the test accuracy of various GCNs increases by 1.21%~2.84%. We open source our implementation at https://github.com/ytchx1999/PyG-OGB-Tricks.