 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Knowledge Distillation: A survey and experimental evaluation
Feb 27, 2023Graph, such as citation networks, social networks, and transportation networks, are prevalent in the real world. Graph Neural Networks (GNNs) have gained widespread attention for their robust expressiveness and exceptional performance in various graph applications. However, the efficacy of GNNs is heavily reliant on sufficient data labels and complex network models, with the former obtaining hardly and the latter computing costly. To address the labeled data scarcity and high complexity of GNNs, Knowledge Distillation (KD) has been introduced to enhance existing GNNs. This technique involves transferring the soft-label supervision of the large teacher model to the small student model while maintaining prediction performance. This survey offers a comprehensive overview of Graph-based Knowledge Distillation methods, systematically categorizing and summarizing them while discussing their limitations and future directions. This paper first introduces the background of graph and KD. It then provides a comprehensive summary of three types of Graph-based Knowledge Distillation methods, namely Graph-based Knowledge Distillation for deep neural networks (DKD), Graph-based Knowledge Distillation for GNNs (GKD), and Self-Knowledge Distillation based Graph-based Knowledge Distillation (SKD). Each type is further divided into knowledge distillation methods based on the output layer, middle layer, and constructed graph. Subsequently, various algorithms' ideas are analyzed and compared, concluding with the advantages and disadvantages of each algorithm supported by experimental results. In addition, the applications of graph-based knowledge distillation in CV, NLP, RS, and other fields are listed. Finally, the graph-based knowledge distillation is summarized and prospectively discussed. We have also released related resources at https://github.com/liujing1023/Graph-based-Knowledge-Distillation.
Long Short-Term Preference Modeling for Continuous-Time Sequential Recommendation
Aug 01, 2022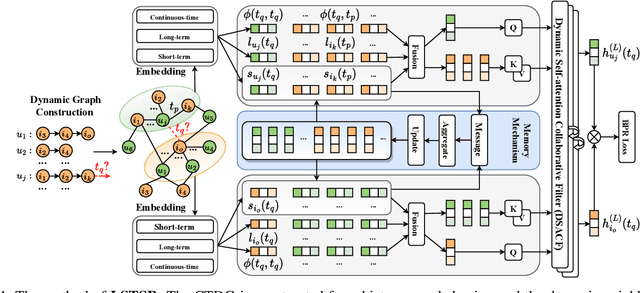

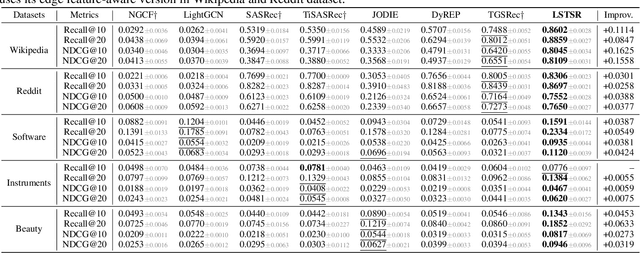
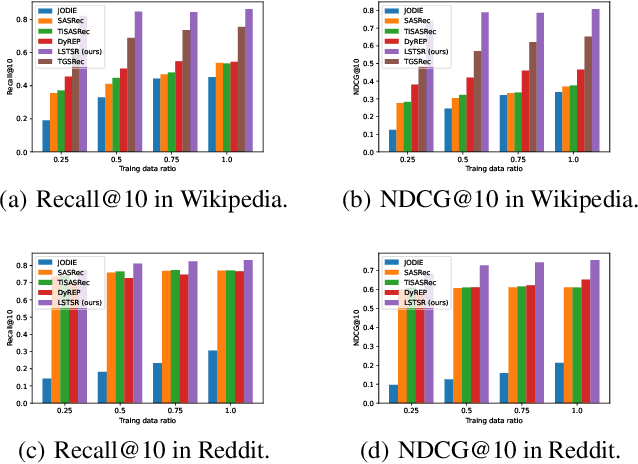
Modeling the evolution of user preference is essential in recommender systems. Recently, dynamic graph-based methods have been studied and achieved SOTA for recommendation, majority of which focus on user's stable long-term preference. However, in real-world scenario, user's short-term preference evolves over time dynamically. Although there exists sequential methods that attempt to capture it, how to model the evolution of short-term preference with dynamic graph-based methods has not been well-addressed yet. In particular: 1) existing methods do not explicitly encode and capture the evolution of short-term preference as sequential methods do; 2) simply using last few interactions is not enough for modeling the changing trend. In this paper, we propose Long Short-Term Preference Modeling for Continuous-Time Sequential Recommendation (LSTSR) to capture the evolution of short-term preference under dynamic graph. Specifically, we explicitly encode short-term preference and optimize it via memory mechanism, which has three key operations: Message, Aggregate and Update. Our memory mechanism can not only store one-hop information, but also trigger with new interactions online. Extensive experiments conducted on five public datasets show that LSTSR consistently outperforms many state-of-the-art recommendation methods across various lines.
HIRE: Distilling High-order Relational Knowledge From Heterogeneous Graph Neural Networks
Jul 25, 2022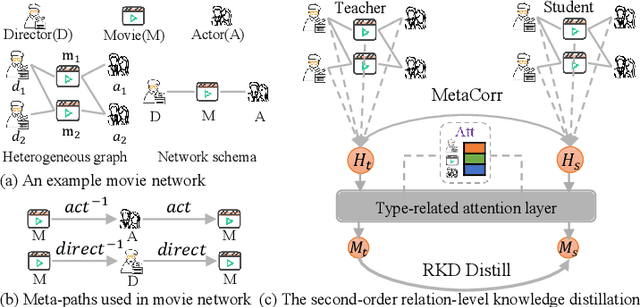

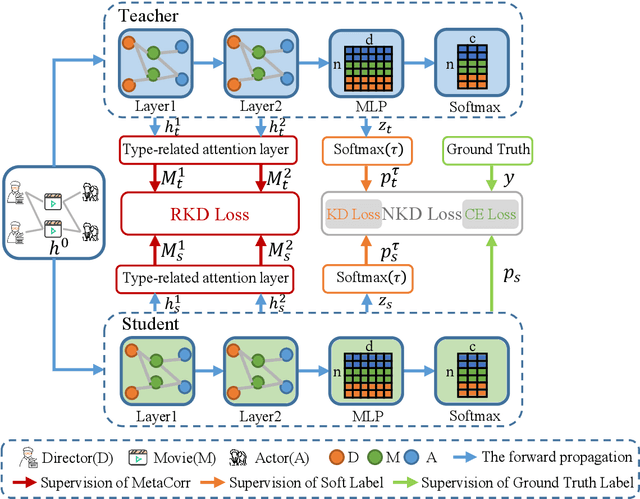

Researchers have recently proposed plenty of heterogeneous graph neural networks (HGNNs) due to the ubiquity of heterogeneous graphs in both academic and industrial areas. Instead of pursuing a more powerful HGNN model, in this paper, we are interested in devising a versatile plug-and-play module, which accounts for distilling relational knowledge from pre-trained HGNNs. To the best of our knowledge, we are the first to propose a HIgh-order RElational (HIRE) knowledge distillation framework on heterogeneous graphs, which can significantly boost the prediction performance regardless of model architectures of HGNNs. Concretely, our HIRE framework initially performs first-order node-level knowledge distillation, which encodes the semantics of the teacher HGNN with its prediction logits. Meanwhile, the second-order relation-level knowledge distillation imitates the relational correlation between node embeddings of different types generated by the teacher HGNN. Extensive experiments on various popular HGNNs models and three real-world heterogeneous graphs demonstrate that our method obtains consistent and considerable performance enhancement, proving its effectiveness and generalization ability.
Residual Network and Embedding Usage: New Tricks of Node Classification with Graph Convolutional Networks
May 21, 2021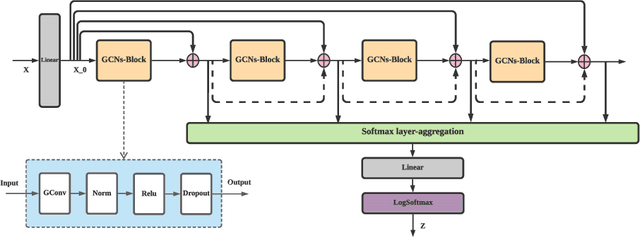
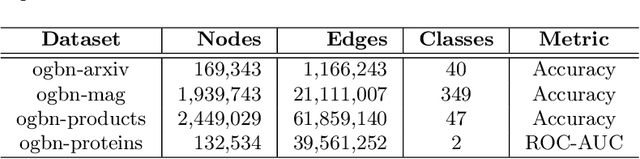
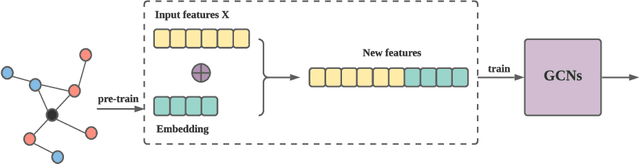
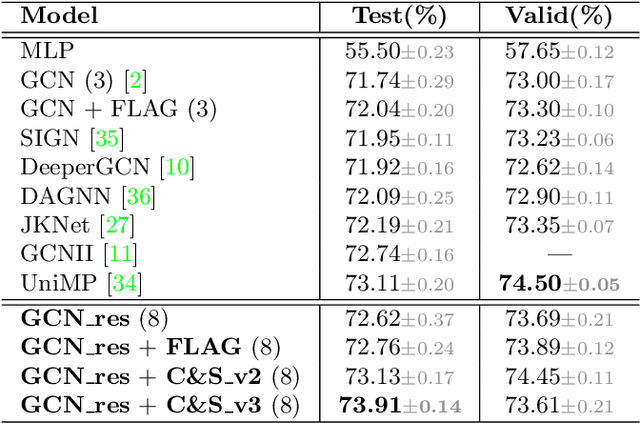
Graph Convolutional Networks (GCNs) and subsequent variants have been proposed to solve tasks on graphs, especially node classification tasks. In the literature, however, most tricks or techniques are either briefly mentioned as implementation details or only visible in source code. In this paper, we first summarize some existing effective tricks used in GCNs mini-batch training. Based on this, two novel tricks named GCN_res Framework and Embedding Usage are proposed by leveraging residual network and pre-trained embedding to improve baseline's test accuracy in different datasets. Experiments on Open Graph Benchmark (OGB) show that, by combining these techniques, the test accuracy of various GCNs increases by 1.21%~2.84%. We open source our implementation at https://github.com/ytchx1999/PyG-OGB-Tricks.