 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRE: Robust and Effective Federated Learning with Privacy Preference
May 08, 2025
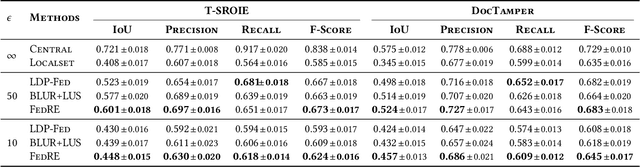
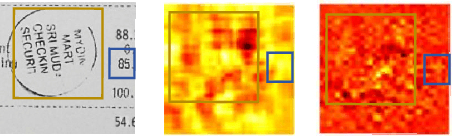
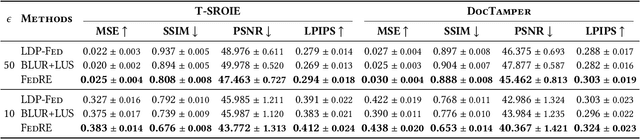
Despite Federated Learning (FL) employing gradient aggregation at the server for distributed training to prevent the privacy leakage of raw data, private information can still be divulged through the analysis of uploaded gradients from clients. Substantial efforts have been made to integrate local differential privacy (LDP) into the system to achieve a strict privacy guarantee. However, existing methods fail to take practical issues into account by merely perturbing each sample with the same mechanism while each client may have their own privacy preferences on privacy-sensitive information (PSI), which is not uniformly distributed across the raw data. In such a case, excessive privacy protection from private-insensitive information can additionally introduce unnecessary noise, which may degrade the model performance. In this work, we study the PSI within data and develop FedRE, that can simultaneously achieve robustness and effectiveness benefits with LDP protection. More specifically, we first define PSI with regard to the privacy preferences of each client. Then, we optimize the LDP by allocating less privacy budget to gradients with higher PSI in a layer-wise manner, thus providing a stricter privacy guarantee for PSI. Furthermore, to mitigate the performance degradation caused by LDP, we design a parameter aggregation mechanism based on the distribution of the perturbed information. We conducted experiments with text tamper detection on T-SROIE and DocTamper datasets, and FedRE achieves competitive performance compared to state-of-the-art methods.
FedGIG: Graph Inversion from Gradient in Federated Learning
Dec 24, 2024



Recent studies have shown that Federated learning (FL) is vulnerable to Gradient Inversion Attacks (GIA), which can recover private training data from shared gradients. However, existing methods are designed for dense, continuous data such as images or vectorized texts, and cannot be directly applied to sparse and discrete graph data. This paper first explores GIA's impact on Federated Graph Learning (FGL) and introduces Graph Inversion from Gradient in Federated Learning (FedGIG), a novel GIA method specifically designed for graph-structured data. FedGIG includes the adjacency matrix constraining module, which ensures the sparsity and discreteness of the reconstructed graph data, and the subgraph reconstruction module, which is designed to complete missing common subgraph structures. Extensive experiments on molecular datasets demonstrate FedGIG's superior accuracy over existing GIA techniques.
Unleashing the Power of Continual Learning on Non-Centralized Devices: A Survey
Dec 18, 2024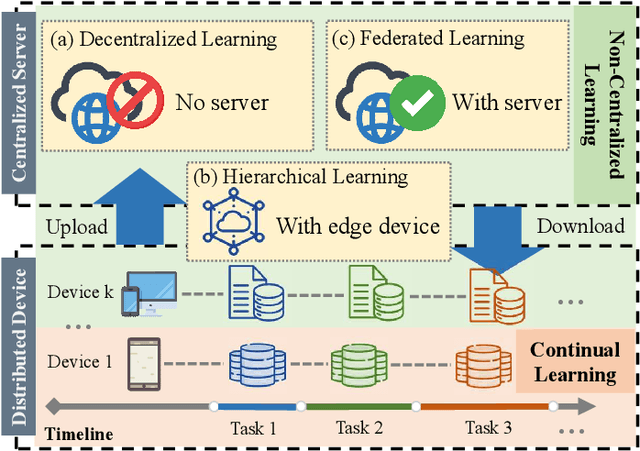
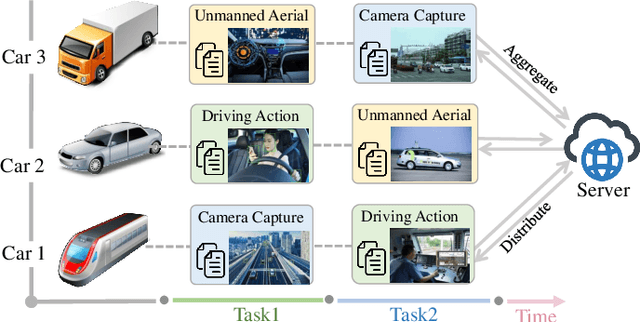
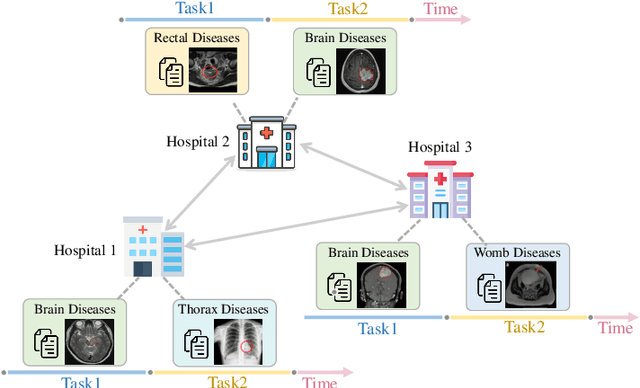
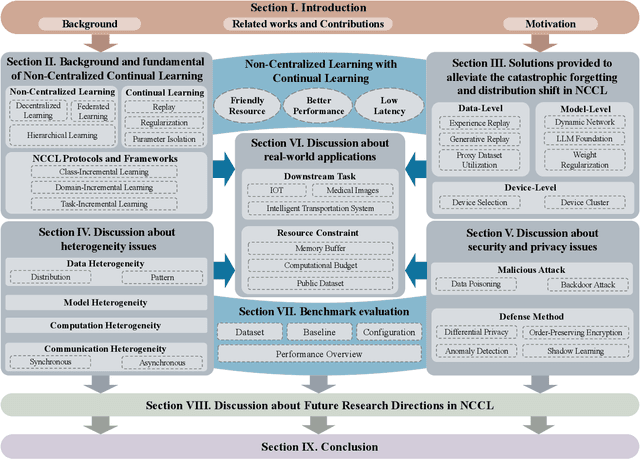
Non-Centralized Continual Learning (NCCL) has become an emerging paradigm for enabling distributed devices such as vehicles and servers to handle streaming data from a joint non-stationary environment. To achieve high reliability and scalability in deploying this paradigm in distributed systems, it is essential to conquer challenges stemming from both spatial and temporal dimensions, manifesting as distribution shifts, catastrophic forgetting, heterogeneity, and privacy issues. This survey focuses on a comprehensive examination of the development of the non-centralized continual learning algorithms and the real-world deployment across distributed devices. We begin with an introduction to the background and fundamentals of non-centralized learning and continual learning. Then, we review existing solutions from three levels to represent how existing techniques alleviate the catastrophic forgetting and distribution shift. Additionally, we delve into the various types of heterogeneity issues, security, and privacy attributes, as well as real-world applications across three prevalent scenarios. Furthermore, we establish a large-scale benchmark to revisit this problem and analyze the performance of the state-of-the-art NCCL approaches. Finally, we discuss the important challenges and future research directions in NCCL.
Rehearsal-Free Continual Federated Learning with Synergistic Regularization
Dec 18, 2024



Continual Federated Learning (CFL) allows distributed devices to collaboratively learn novel concepts from continuously shifting training data while avoiding knowledge forgetting of previously seen tasks. To tackle this challenge, most current CFL approaches rely on extensive rehearsal of previous data. Despite effectiveness, rehearsal comes at a cost to memory, and it may also violate data privacy. Considering these, we seek to apply regularization techniques to CFL by considering their cost-efficient properties that do not require sample caching or rehearsal. Specifically, we first apply traditional regularization techniques to CFL and observe that existing regularization techniques, especially synaptic intelligence, can achieve promising results under homogeneous data distribution but fail when the data is heterogeneous. Based on this observation, we propose a simple yet effective regularization algorithm for CFL named FedSSI, which tailors the synaptic intelligence for the CFL with heterogeneous data settings. FedSSI can not only reduce computational overhead without rehearsal but also address the data heterogeneity issue. Extensive experiments show that FedSSI achieves superior performance compared to state-of-the-art methods.