 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Image Modeling for Self-Supervised Vision Representation Learning
Paper and Code
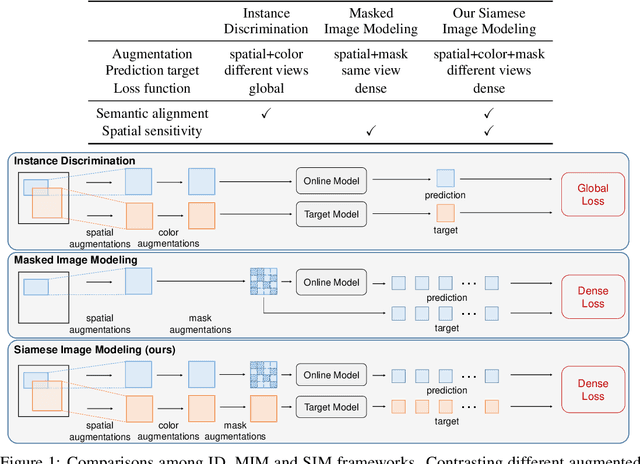

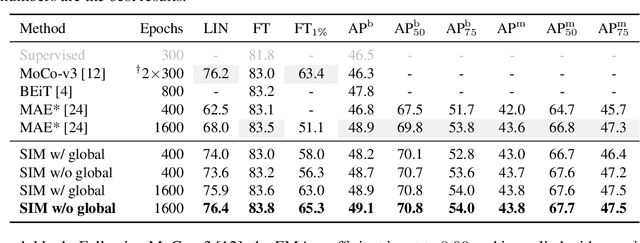
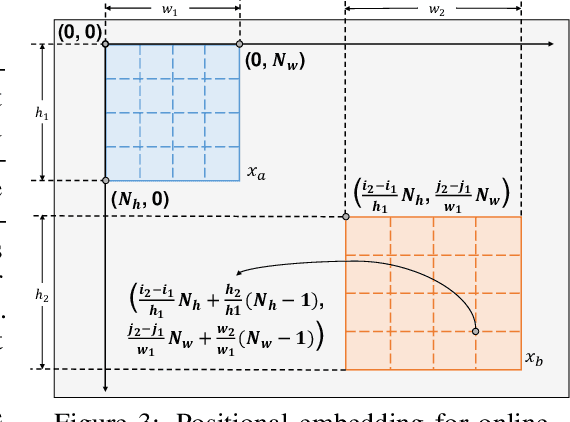
Self-supervised learning (SSL) has delivered superior performance on a variety of downstream vision tasks. Two main-stream SSL frameworks have been proposed, i.e., Instance Discrimination (ID) and Masked Image Modeling (MIM). ID pulls together the representations of different views from the same image, while avoiding feature collapse. It does well on linear probing but is inferior in detection performance. On the other hand, MIM reconstructs the original content given a masked image. It excels at dense prediction but fails to perform well on linear probing. Their distinctions are caused by neglecting the representation requirements of either semantic alignment or spatial sensitivity. Specifically, we observe that (1) semantic alignment demands semantically similar views to be projected into nearby representation, which can be achieved by contrasting different views with strong augmentations; (2) spatial sensitivity requires to model the local structure within an image. Predicting dense representations with masked image is therefore beneficial because it models the conditional distribution of image content. Driven by these analysis, we propose Siamese Image Modeling (SIM), which predicts the dense representations of an augmented view, based on another masked view from the same image but with different augmentations. Our method uses a Siamese network with two branches. The online branch encodes the first view, and predicts the second view's representation according to the relative positions between these two views. The target branch produces the target by encoding the second view. In this way, we are able to achieve comparable linear probing and dense prediction performances with ID and MIM, respectively. We also demonstrate that decent linear probing result can be obtained without a global loss. Code shall be released.