 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Aerial Detection Baseline of Multimodal Language Models
Jan 16, 2025



The multimodal language models (MLMs) based on generative pre-trained Transformer are considered powerful candidates for unifying various domains and tasks. MLMs developed for remote sensing (RS) have demonstrated outstanding performance in multiple tasks, such as visual question answering and visual grounding. In addition to visual grounding that detects specific objects corresponded to given instruction, aerial detection, which detects all objects of multiple categories, is also a valuable and challenging task for RS foundation models. However, aerial detection has not been explored by existing RS MLMs because the autoregressive prediction mechanism of MLMs differs significantly from the detection outputs. In this paper, we present a simple baseline for applying MLMs to aerial detection for the first time, named LMMRotate. Specifically, we first introduce a normalization method to transform detection outputs into textual outputs to be compatible with the MLM framework. Then, we propose a evaluation method, which ensures a fair comparison between MLMs and conventional object detection models. We construct the baseline by fine-tuning open-source general-purpose MLMs and achieve impressive detection performance comparable to conventional detector. We hope that this baseline will serve as a reference for future MLM development, enabling more comprehensive capabilities for understanding RS images. Code is available at https://github.com/Li-Qingyun/mllm-mmrotate.
OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 13, 2024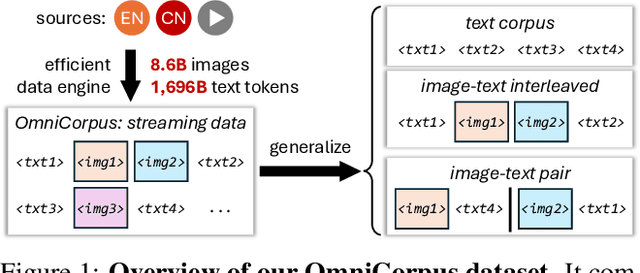
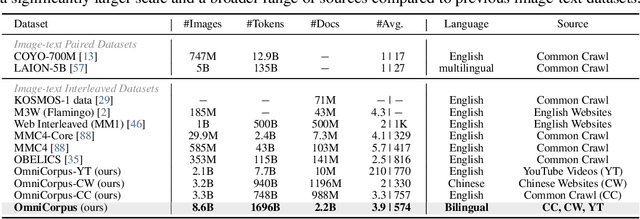

Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.
OmniCorpus: An Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 12, 2024Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.
Spectral-Spatial Mamba for Hyperspectral Image Classification
Apr 29, 2024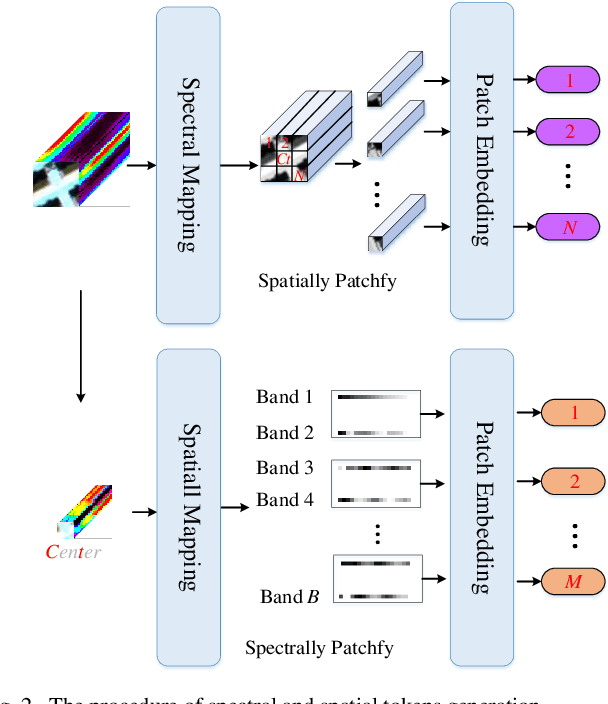
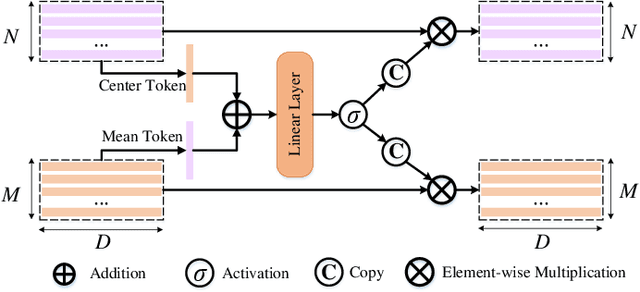
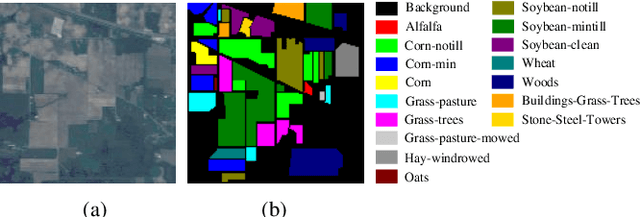

Recently, deep learning models have achieved excellent performance in hyperspectral image (HSI) classification. Among the many deep models, Transformer has gradually attracted interest for its excellence in modeling the long-range dependencies of spatial-spectral features in HSI. However, Transformer has the problem of quadratic computational complexity due to the self-attention mechanism, which is heavier than other models and thus has limited adoption in HSI processing. Fortunately, the recently emerging state space model-based Mamba shows great computational efficiency while achieving the modeling power of Transformers. Therefore, in this paper, we make a preliminary attempt to apply the Mamba to HSI classification, leading to the proposed spectral-spatial Mamba (SS-Mamba). Specifically, the proposed SS-Mamba mainly consists of spectral-spatial token generation module and several stacked spectral-spatial Mamba blocks. Firstly, the token generation module converts any given HSI cube to spatial and spectral tokens as sequences. And then these tokens are sent to stacked spectral-spatial mamba blocks (SS-MB). Each SS-MB block consists of two basic mamba blocks and a spectral-spatial feature enhancement module. The spatial and spectral tokens are processed separately by the two basic mamba blocks, respectively. Besides, the feature enhancement module modulates spatial and spectral tokens using HSI sample's center region information. In this way, the spectral and spatial tokens cooperate with each other and achieve information fusion within each block. The experimental results conducted on widely used HSI datasets reveal that the proposed model achieves competitive results compared with the state-of-the-art methods. The Mamba-based method opens a new window for HSI classification.
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
Aug 03, 2023We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world. Using a scalable data engine that incorporates human feedback and efficient models in the loop, we create a new dataset (AS-1B) with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes. Leveraging this new dataset, we develop the All-Seeing model (ASM), a unified framework for panoptic visual recognition and understanding. The model is trained with open-ended language prompts and locations, which allows it to generalize to various vision and language tasks with remarkable zero-shot performance, including region-text retrieval, region recognition, captioning, and question-answering. We hope that this project can serve as a foundation for vision-language artificial general intelligence research. Models and the dataset shall be released at https://github.com/OpenGVLab/All-Seeing, and demo can be seen at https://huggingface.co/spaces/OpenGVLab/all-seeing.
ARS-DETR: Aspect Ratio Sensitive Oriented Object Detection with Transformer
Mar 09, 2023Existing oriented object detection methods commonly use metric AP$_{50}$ to measure the performance of the model. We argue that AP$_{50}$ is inherently unsuitable for oriented object detection due to its large tolerance in angle deviation. Therefore, we advocate using high-precision metric, e.g. AP$_{75}$, to measure the performance of models. In this paper, we propose an Aspect Ratio Sensitive Oriented Object Detector with Transformer, termed ARS-DETR, which exhibits a competitive performance in high-precision oriented object detection. Specifically, a new angle classification method, calling Aspect Ratio aware Circle Smooth Label (AR-CSL), is proposed to smooth the angle label in a more reasonable way and discard the hyperparameter that introduced by previous work (e.g. CSL). Then, a rotated deformable attention module is designed to rotate the sampling points with the corresponding angles and eliminate the misalignment between region features and sampling points. Moreover, a dynamic weight coefficient according to the aspect ratio is adopted to calculate the angle loss. Comprehensive experiments on several challenging datasets show that our method achieves competitive performance on the high-precision oriented object detection task.
Deep Learning for Hyperspectral Image Classification: An Overview
Oct 26, 2019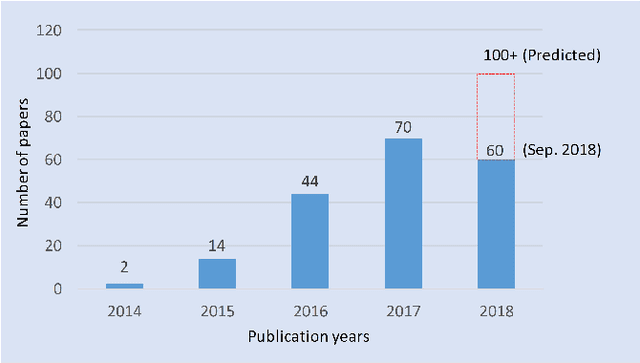
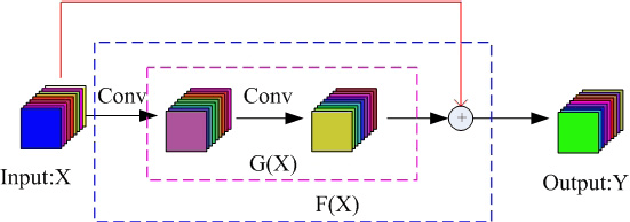
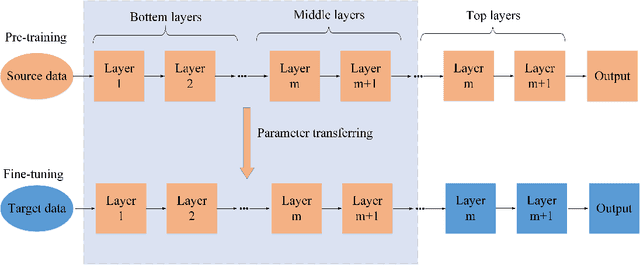
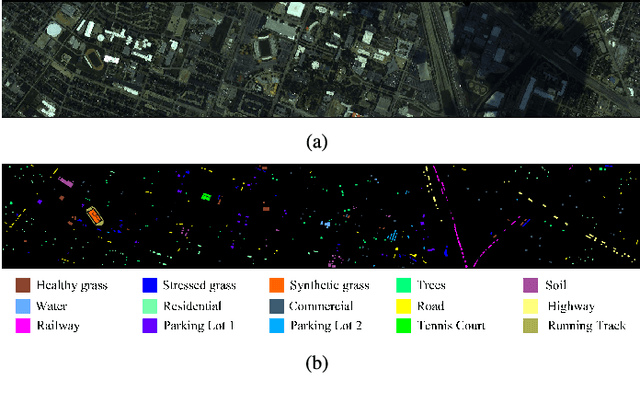
Hyperspectral image (HSI) classification has become a hot topic in the field of remote sensing. In general, the complex characteristics of hyperspectral data make the accurate classification of such data challenging for traditional machine learning methods. In addition, hyperspectral imaging often deals with an inherently nonlinear relation between the captured spectral information and the corresponding materials. In recent years, deep learning has been recognized as a powerful feature-extraction tool to effectively address nonlinear problems and widely used in a number of image processing tasks. Motivated by those successful applications, deep learning has also been introduced to classify HSIs and demonstrated good performance. This survey paper presents a systematic review of deep learning-based HSI classification literatures and compares several strategies for this topic. Specifically, we first summarize the main challenges of HSI classification which cannot be effectively overcome by traditional machine learning methods, and also introduce the advantages of deep learning to handle these problems. Then, we build a framework which divides the corresponding works into spectral-feature networks, spatial-feature networks, and spectral-spatial-feature networks to systematically review the recent achievements in deep learning-based HSI classification. In addition, considering the fact that available training samples in the remote sensing field are usually very limited and training deep networks require a large number of samples, we include some strategies to improve classification performance, which can provide some guidelines for future studies on this topic. Finally, several representative deep learning-based classification methods are conducted on real HSIs in our experiments.
Spectral-Spatial Classification of Hyperspectral Image Using Autoencoders
Nov 09, 2015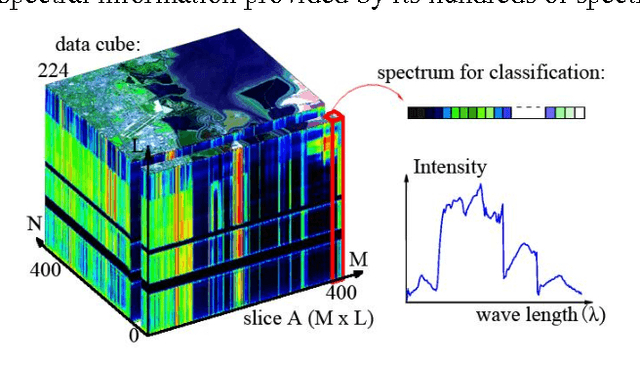
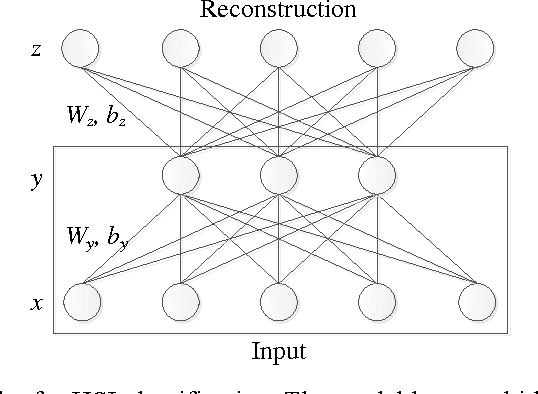
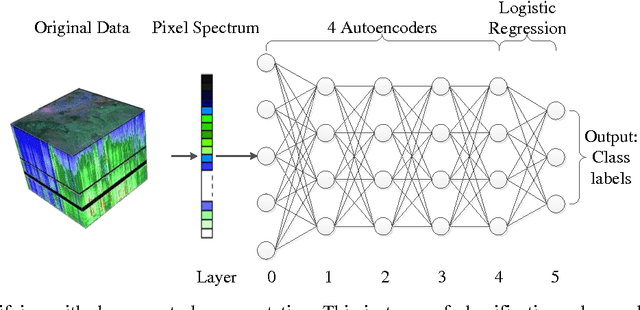
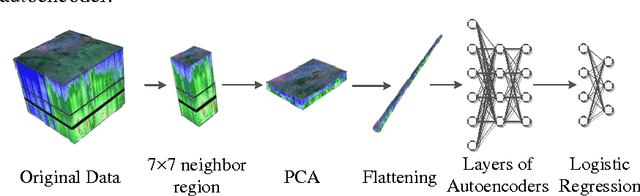
Hyperspectral image (HSI) classification is a hot topic in the remote sensing community. This paper proposes a new framework of spectral-spatial feature extraction for HSI classification, in which for the first time the concept of deep learning is introduced. Specifically, the model of autoencoder is exploited in our framework to extract various kinds of features. First we verify the eligibility of autoencoder by following classical spectral information based classification and use autoencoders with different depth to classify hyperspectral image. Further in the proposed framework, we combine PCA on spectral dimension and autoencoder on the other two spatial dimensions to extract spectral-spatial information for classification. The experimental results show that this framework achieves the highest classification accuracy among all methods, and outperforms classical classifiers such as SVM and PCA-based SVM.