 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
Aug 03, 2023We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world. Using a scalable data engine that incorporates human feedback and efficient models in the loop, we create a new dataset (AS-1B) with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes. Leveraging this new dataset, we develop the All-Seeing model (ASM), a unified framework for panoptic visual recognition and understanding. The model is trained with open-ended language prompts and locations, which allows it to generalize to various vision and language tasks with remarkable zero-shot performance, including region-text retrieval, region recognition, captioning, and question-answering. We hope that this project can serve as a foundation for vision-language artificial general intelligence research. Models and the dataset shall be released at https://github.com/OpenGVLab/All-Seeing, and demo can be seen at https://huggingface.co/spaces/OpenGVLab/all-seeing.
Demystify Transformers & Convolutions in Modern Image Deep Networks
Nov 10, 2022



Recent success of vision transformers has inspired a series of vision backbones with novel feature transformation paradigms, which report steady performance gain. Although the novel feature transformation designs are often claimed as the source of gain, some backbones may benefit from advanced engineering techniques, which makes it hard to identify the real gain from the key feature transformation operators. In this paper, we aim to identify real gain of popular convolution and attention operators and make an in-depth study of them. We observe that the main difference among these feature transformation modules, e.g., attention or convolution, lies in the way of spatial feature aggregation, or the so-called "spatial token mixer" (STM). Hence, we first elaborate a unified architecture to eliminate the unfair impact of different engineering techniques, and then fit STMs into this architecture for comparison. Based on various experiments on upstream/downstream tasks and the analysis of inductive bias, we find that the engineering techniques boost the performance significantly, but the performance gap still exists among different STMs. The detailed analysis also reveals some interesting findings of different STMs, such as effective receptive fields and invariance tests. The code and trained models will be publicly available at https://github.com/OpenGVLab/STM-Evaluation
Convolutional Character Networks
Oct 17, 2019
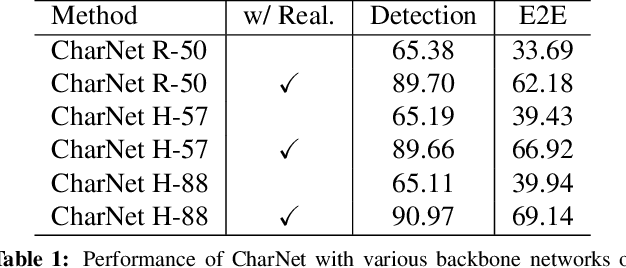
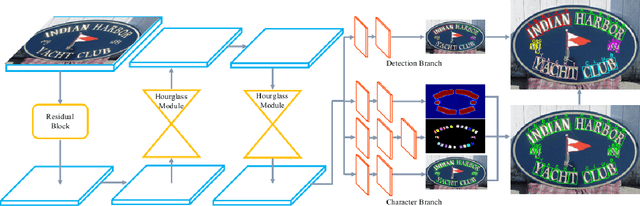
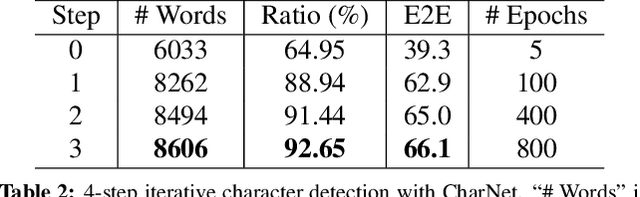
Recent progress has been made on developing a unified framework for joint text detection and recognition in natural images, but existing joint models were mostly built on two-stage framework by involving ROI pooling, which can degrade the performance on recognition task. In this work, we propose convolutional character networks, referred as CharNet, which is an one-stage model that can process two tasks simultaneously in one pass. CharNet directly outputs bounding boxes of words and characters, with corresponding character labels. We utilize character as basic element, allowing us to overcome the main difficulty of existing approaches that attempted to optimize text detection jointly with a RNN-based recognition branch. In addition, we develop an iterative character detection approach able to transform the ability of character detection learned from synthetic data to real-world images. These technical improvements result in a simple, compact, yet powerful one-stage model that works reliably on multi-orientation and curved text. We evaluate CharNet on three standard benchmarks, where it consistently outperforms the state-of-the-art approaches [25, 24] by a large margin, e.g., with improvements of 65.33%->71.08% (with generic lexicon) on ICDAR 2015, and 54.0%->69.23% on Total-Text, on end-to-end text recognition. Code is available at: https://github.com/MalongTech/research-charnet.
DeepWriter: A Multi-Stream Deep CNN for Text-independent Writer Identification
Aug 03, 2016



Text-independent writer identification is challenging due to the huge variation of written contents and the ambiguous written styles of different writers. This paper proposes DeepWriter, a deep multi-stream CNN to learn deep powerful representation for recognizing writers. DeepWriter takes local handwritten patches as input and is trained with softmax classification loss. The main contributions are: 1) we design and optimize multi-stream structure for writer identification task; 2) we introduce data augmentation learning to enhance the performance of DeepWriter; 3) we introduce a patch scanning strategy to handle text image with different lengths. In addition, we find that different languages such as English and Chinese may share common features for writer identification, and joint training can yield better performance. Experimental results on IAM and HWDB datasets show that our models achieve high identification accuracy: 99.01% on 301 writers and 97.03% on 657 writers with one English sentence input, 93.85% on 300 writers with one Chinese character input, which outperform previous methods with a large margin. Moreover, our models obtain accuracy of 98.01% on 301 writers with only 4 English alphabets as input.