 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
Aug 03, 2023We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world. Using a scalable data engine that incorporates human feedback and efficient models in the loop, we create a new dataset (AS-1B) with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes. Leveraging this new dataset, we develop the All-Seeing model (ASM), a unified framework for panoptic visual recognition and understanding. The model is trained with open-ended language prompts and locations, which allows it to generalize to various vision and language tasks with remarkable zero-shot performance, including region-text retrieval, region recognition, captioning, and question-answering. We hope that this project can serve as a foundation for vision-language artificial general intelligence research. Models and the dataset shall be released at https://github.com/OpenGVLab/All-Seeing, and demo can be seen at https://huggingface.co/spaces/OpenGVLab/all-seeing.
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Nov 13, 2022



Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. The code will be released at https://github.com/OpenGVLab/InternImage.
ForgeryNet -- Face Forgery Analysis Challenge 2021: Methods and Results
Dec 15, 2021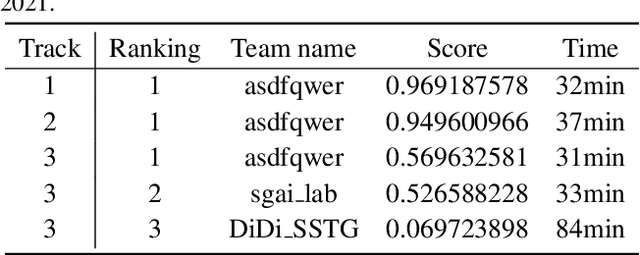
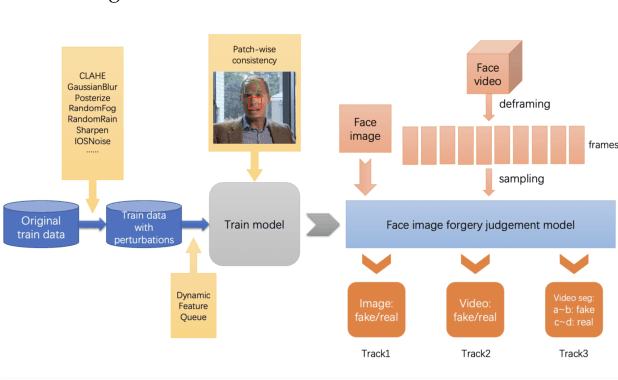
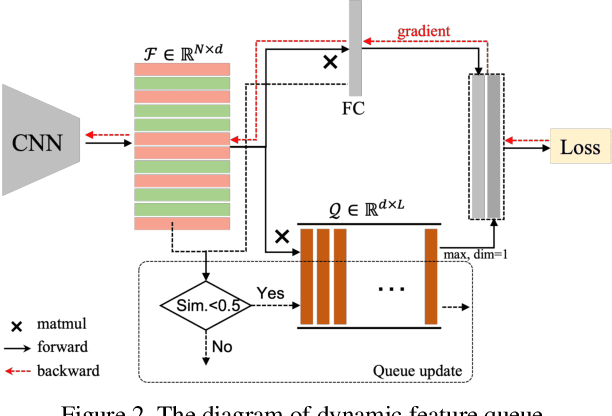
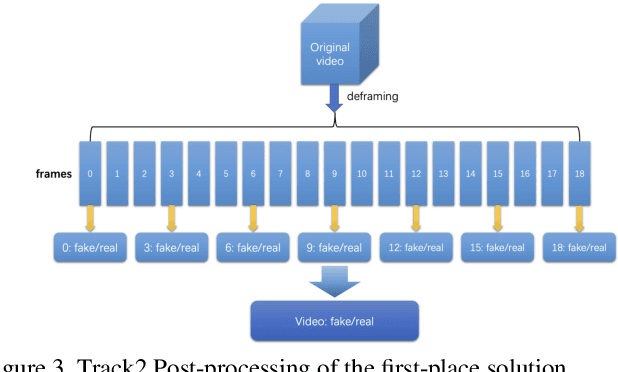
The rapid progress of photorealistic synthesis techniques has reached a critical point where the boundary between real and manipulated images starts to blur. Recently, a mega-scale deep face forgery dataset, ForgeryNet which comprised of 2.9 million images and 221,247 videos has been released. It is by far the largest publicly available in terms of data-scale, manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations), and annotations (6.3 million classification labels, 2.9 million manipulated area annotations, and 221,247 temporal forgery segment labels). This paper reports methods and results in the ForgeryNet - Face Forgery Analysis Challenge 2021, which employs the ForgeryNet benchmark. The model evaluation is conducted offline on the private test set. A total of 186 participants registered for the competition, and 11 teams made valid submissions. We will analyze the top-ranked solutions and present some discussion on future work directions.
iShape: A First Step Towards Irregular Shape Instance Segmentation
Sep 30, 2021In this paper, we introduce a brand new dataset to promote the study of instance segmentation for objects with irregular shapes. Our key observation is that though irregularly shaped objects widely exist in daily life and industrial scenarios, they received little attention in the instance segmentation field due to the lack of corresponding datasets. To fill this gap, we propose iShape, an irregular shape dataset for instance segmentation. iShape contains six sub-datasets with one real and five synthetics, each represents a scene of a typical irregular shape. Unlike most existing instance segmentation datasets of regular objects, iShape has many characteristics that challenge existing instance segmentation algorithms, such as large overlaps between bounding boxes of instances, extreme aspect ratios, and large numbers of connected components per instance. We benchmark popular instance segmentation methods on iShape and find their performance drop dramatically. Hence, we propose an affinity-based instance segmentation algorithm, called ASIS, as a stronger baseline. ASIS explicitly combines perception and reasoning to solve Arbitrary Shape Instance Segmentation including irregular objects. Experimental results show that ASIS outperforms the state-of-the-art on iShape. Dataset and code are available at https://ishape.github.io
Fast Single-shot Ship Instance Segmentation Based on Polar Template Mask in Remote Sensing Images
Aug 28, 2020Object detection and instance segmentation in remote sensing images is a fundamental and challenging task, due to the complexity of scenes and targets. The latest methods tried to take into account both the efficiency and the accuracy of instance segmentation. In order to improve both of them, in this paper, we propose a single-shot convolutional neural network structure, which is conceptually simple and straightforward, and meanwhile makes up for the problem of low accuracy of single-shot networks. Our method, termed with SSS-Net, detects targets based on the location of the object's center and the distances between the center and the points on the silhouette sampling with non-uniform angle intervals, thereby achieving abalanced sampling of lines in mask generation. In addition, we propose a non-uniform polar template IoU based on the contour template in polar coordinates. Experiments on both the Airbus Ship Detection Challenge dataset and the ISAIDships dataset show that SSS-Net has strong competitiveness in precision and speed for ship instance segmentation.