 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation Leveraging Alternative Soft Targets from Non-Parallel Qualified Speech Data
Paper and Code
Dec 16, 2021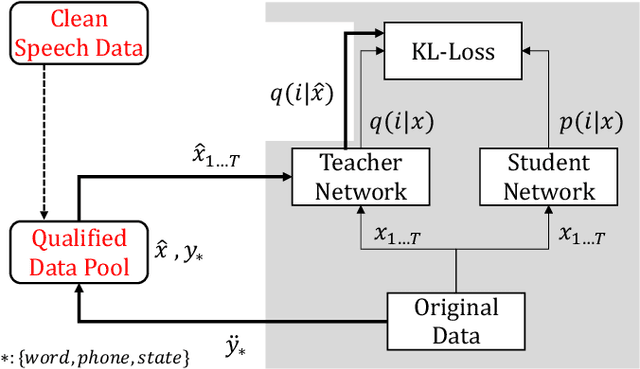
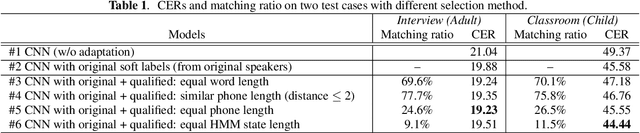
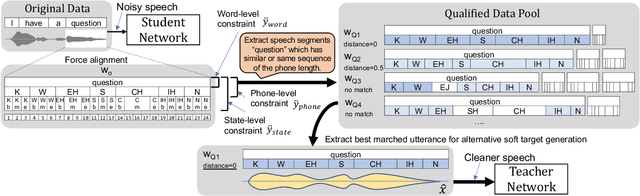
This paper describes a novel knowledge distillation framework that leverages acoustically qualified speech data included in an existing training data pool as privileged information. In our proposed framework, a student network is trained with multiple soft targets for each utterance that consist of main soft targets from original speakers' utterance and alternative targets from other speakers' utterances spoken under better acoustic conditions as a secondary view. These qualified utterances from other speakers, used to generate better soft targets, are collected from a qualified data pool by using strict constraints in terms of word/phone/state durations. Our proposed method is a form of target-side data augmentation that creates multiple copies of data with corresponding better soft targets obtained from a qualified data pool. We show in our experiments under acoustic model adaptation settings that the proposed method, exploiting better soft targets obtained from various speakers, can further improve recognition accuracy compared with conventional methods using only soft targets from original speakers.