 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNN Transducer Models For Spoken Language Understanding
Paper and Code
Apr 08, 2021
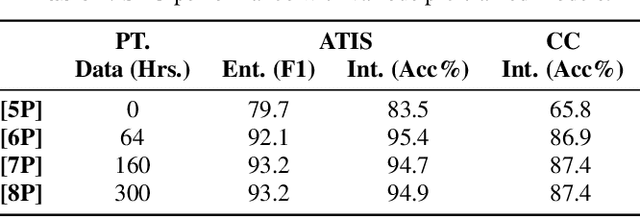


We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.