 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
HGAN-SDEs: Learning Neural Stochastic Differential Equations with Hermite-Guided Adversarial Training
Dec 23, 2025Neural Stochastic Differential Equations (Neural SDEs) provide a principled framework for modeling continuous-time stochastic processes and have been widely adopted in fields ranging from physics to finance. Recent advances suggest that Generative Adversarial Networks (GANs) offer a promising solution to learning the complex path distributions induced by SDEs. However, a critical bottleneck lies in designing a discriminator that faithfully captures temporal dependencies while remaining computationally efficient. Prior works have explored Neural Controlled Differential Equations (CDEs) as discriminators due to their ability to model continuous-time dynamics, but such architectures suffer from high computational costs and exacerbate the instability of adversarial training. To address these limitations, we introduce HGAN-SDEs, a novel GAN-based framework that leverages Neural Hermite functions to construct a structured and efficient discriminator. Hermite functions provide an expressive yet lightweight basis for approximating path-level dynamics, enabling both reduced runtime complexity and improved training stability. We establish the universal approximation property of our framework for a broad class of SDE-driven distributions and theoretically characterize its convergence behavior. Extensive empirical evaluations on synthetic and real-world systems demonstrate that HGAN-SDEs achieve superior sample quality and learning efficiency compared to existing generative models for SDEs
Adapting to the Unknown: Robust Meta-Learning for Zero-Shot Financial Time Series Forecasting
Apr 13, 2025
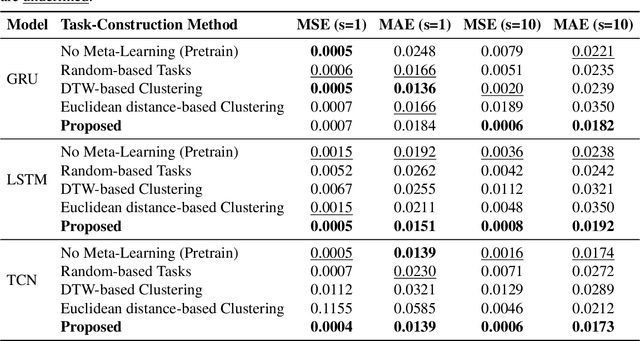

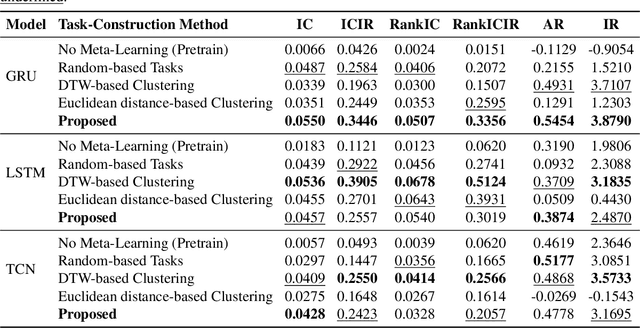
Financial time series forecasting in the zero-shot setting is essential for risk management and investment decision-making, particularly during abrupt market regime shifts or in emerging markets with limited historical data. While Model-Agnostic Meta-Learning (MAML)-based approaches have shown promise in this domain, existing meta task construction strategies often lead to suboptimal performance, especially when dealing with highly turbulent financial time series. To address this challenge, we propose a novel task construction method that leverages learned embeddings for more effective meta-learning in the zero-shot setting. Specifically, we construct two complementary types of meta-tasks based on the learned embeddings: intra-cluster tasks and inter-cluster tasks. To capture diverse fine-grained patterns, we apply stochastic projection matrices to the learned embeddings and use clustering algorithm to form the tasks. Additionally, to improve generalization capabilities, we employ hard task mining strategies and leverage inter-cluster tasks to identify invariant patterns across different time series. Extensive experiments on the real world financial dataset demonstrate that our method significantly outperforms existing approaches, showing better generalization ability in the zero-shot scenario.
PLUTUS: A Well Pre-trained Large Unified Transformer can Unveil Financial Time Series Regularities
Aug 20, 2024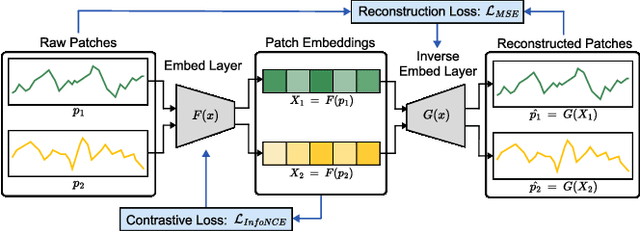
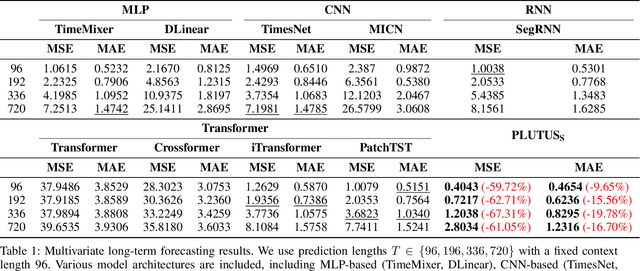

Financial time series modeling is crucial for understanding and predicting market behaviors but faces challenges such as non-linearity, non-stationarity, and high noise levels. Traditional models struggle to capture complex patterns due to these issues, compounded by limitations in computational resources and model capacity. Inspired by the success of large language models in NLP, we introduce $\textbf{PLUTUS}$, a $\textbf{P}$re-trained $\textbf{L}$arge $\textbf{U}$nified $\textbf{T}$ransformer-based model that $\textbf{U}$nveils regularities in financial time $\textbf{S}$eries. PLUTUS uses an invertible embedding module with contrastive learning and autoencoder techniques to create an approximate one-to-one mapping between raw data and patch embeddings. TimeFormer, an attention based architecture, forms the core of PLUTUS, effectively modeling high-noise time series. We incorporate a novel attention mechanisms to capture features across both variable and temporal dimensions. PLUTUS is pre-trained on an unprecedented dataset of 100 billion observations, designed to thrive in noisy financial environments. To our knowledge, PLUTUS is the first open-source, large-scale, pre-trained financial time series model with over one billion parameters. It achieves state-of-the-art performance in various tasks, demonstrating strong transferability and establishing a robust foundational model for finance. Our research provides technical guidance for pre-training financial time series data, setting a new standard in the field.
AbdomenAtlas: A Large-Scale, Detailed-Annotated, & Multi-Center Dataset for Efficient Transfer Learning and Open Algorithmic Benchmarking
Jul 23, 2024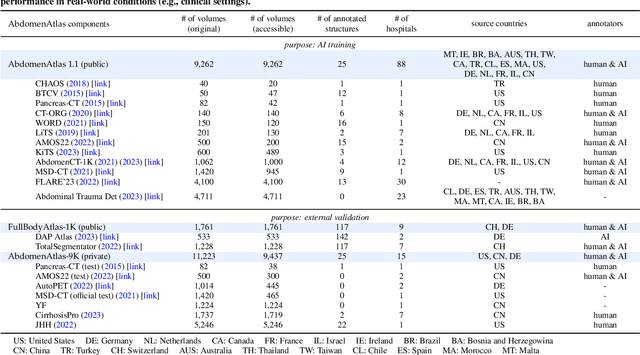


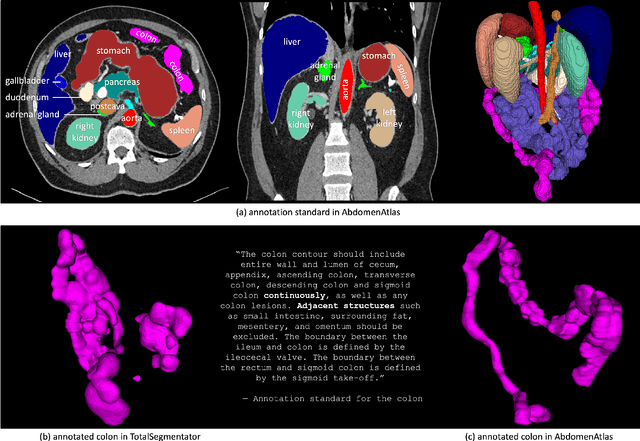
We introduce the largest abdominal CT dataset (termed AbdomenAtlas) of 20,460 three-dimensional CT volumes sourced from 112 hospitals across diverse populations, geographies, and facilities. AbdomenAtlas provides 673K high-quality masks of anatomical structures in the abdominal region annotated by a team of 10 radiologists with the help of AI algorithms. We start by having expert radiologists manually annotate 22 anatomical structures in 5,246 CT volumes. Following this, a semi-automatic annotation procedure is performed for the remaining CT volumes, where radiologists revise the annotations predicted by AI, and in turn, AI improves its predictions by learning from revised annotations. Such a large-scale, detailed-annotated, and multi-center dataset is needed for two reasons. Firstly, AbdomenAtlas provides important resources for AI development at scale, branded as large pre-trained models, which can alleviate the annotation workload of expert radiologists to transfer to broader clinical applications. Secondly, AbdomenAtlas establishes a large-scale benchmark for evaluating AI algorithms -- the more data we use to test the algorithms, the better we can guarantee reliable performance in complex clinical scenarios. An ISBI & MICCAI challenge named BodyMaps: Towards 3D Atlas of Human Body was launched using a subset of our AbdomenAtlas, aiming to stimulate AI innovation and to benchmark segmentation accuracy, inference efficiency, and domain generalizability. We hope our AbdomenAtlas can set the stage for larger-scale clinical trials and offer exceptional opportunities to practitioners in the medical imaging community. Codes, models, and datasets are available at https://www.zongweiz.com/dataset