 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPTNet: A Dual-Path Transformer Architecture for Scene Text Detection
Paper and Code
Aug 21, 2022


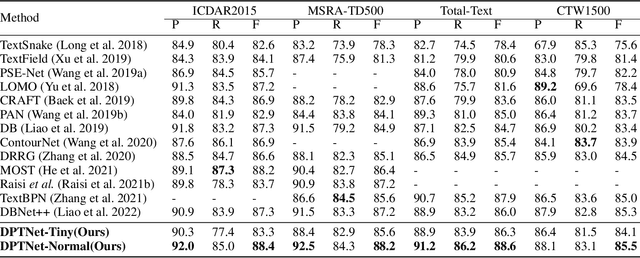
The prosperity of deep learning contributes to the rapid progress in scene text detection. Among all the methods with convolutional networks, segmentation-based ones have drawn extensive attention due to their superiority in detecting text instances of arbitrary shapes and extreme aspect ratios. However, the bottom-up methods are limited to the performance of their segmentation models. In this paper, we propose DPTNet (Dual-Path Transformer Network), a simple yet effective architecture to model the global and local information for the scene text detection task. We further propose a parallel design that integrates the convolutional network with a powerful self-attention mechanism to provide complementary clues between the attention path and convolutional path. Moreover, a bi-directional interaction module across the two paths is developed to provide complementary clues in the channel and spatial dimensions. We also upgrade the concentration operation by adding an extra multi-head attention layer to it. Our DPTNet achieves state-of-the-art results on the MSRA-TD500 dataset, and provides competitive results on other standard benchmarks in terms of both detection accuracy and speed.