 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Uncertainty-Driven Adaptive Self-Alignment Framework for Large Language Models
Jul 23, 2025Large Language Models (LLMs) have demonstrated remarkable progress in instruction following and general-purpose reasoning. However, achieving high-quality alignment with human intent and safety norms without human annotations remains a fundamental challenge. In this work, we propose an Uncertainty-Driven Adaptive Self-Alignment (UDASA) framework designed to improve LLM alignment in a fully automated manner. UDASA first generates multiple responses for each input and quantifies output uncertainty across three dimensions: semantics, factuality, and value alignment. Based on these uncertainty scores, the framework constructs preference pairs and categorizes training samples into three stages, conservative, moderate, and exploratory, according to their uncertainty difference. The model is then optimized progressively across these stages. In addition, we conduct a series of preliminary studies to validate the core design assumptions and provide strong empirical motivation for the proposed framework. Experimental results show that UDASA outperforms existing alignment methods across multiple tasks, including harmlessness, helpfulness, truthfulness, and controlled sentiment generation, significantly improving model performance.
Towards Speeding up Adversarial Training in Latent Spaces
Feb 01, 2021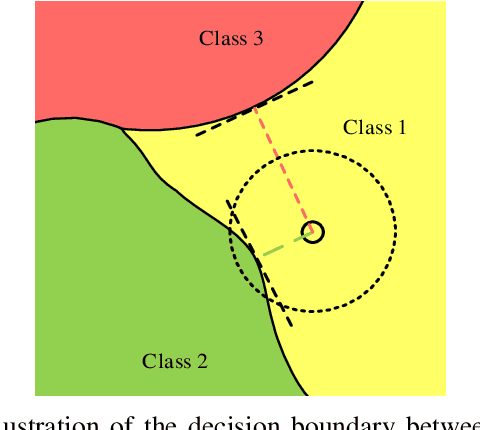
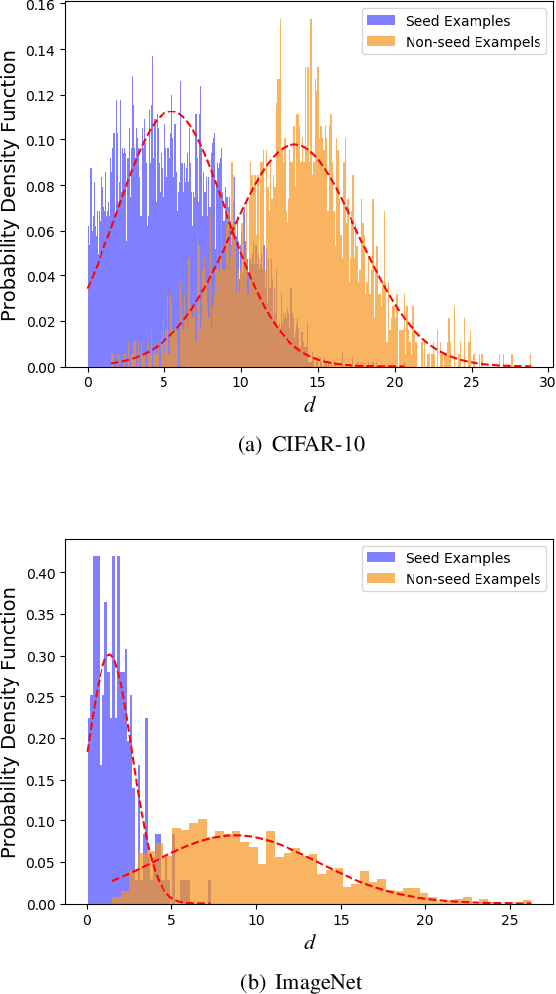
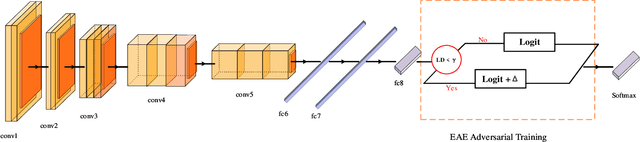
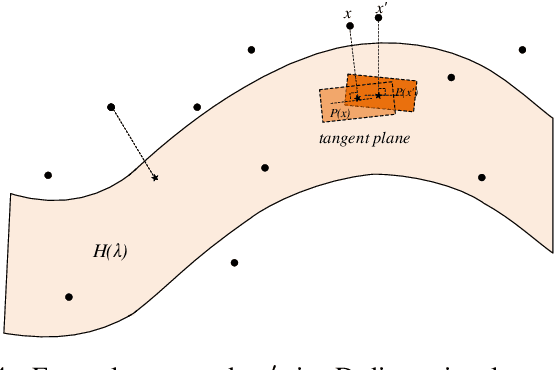
Adversarial training is wildly considered as the most effective way to defend against adversarial examples. However, existing adversarial training methods consume unbearable time cost, since they need to generate adversarial examples in the input space, which accounts for the main part of total time-consuming. For speeding up the training process, we propose a novel adversarial training method that does not need to generate real adversarial examples. We notice that a clean example is closer to the decision boundary of the class with the second largest logit component than any other class besides its own class. Thus, by adding perturbations to logits to generate Endogenous Adversarial Examples(EAEs) -- adversarial examples in the latent space, it can avoid calculating gradients to speed up the training process. We further gain a deep insight into the existence of EAEs by the theory of manifold. To guarantee the added perturbation is within the range of constraint, we use statistical distributions to select seed examples to craft EAEs. Extensive experiments are conducted on CIFAR-10 and ImageNet, and the results show that compare with state-of-the-art "Free" and "Fast" methods, our EAE adversarial training not only shortens the training time, but also enhances the robustness of the model. Moreover, the EAE adversarial training has little impact on the accuracy of clean examples than the existing methods.
Noise Homogenization via Multi-Channel Wavelet Filtering for High-Fidelity Sample Generation in GANs
May 14, 2020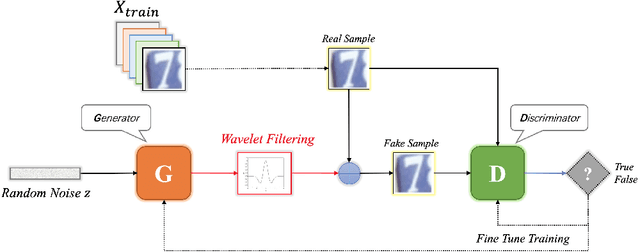

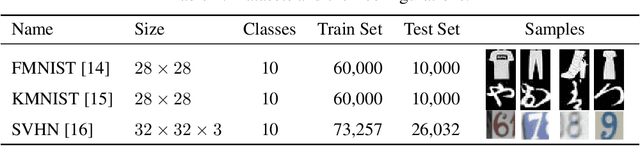

In the generator of typical Generative Adversarial Networks (GANs), a noise is inputted to generate fake samples via a series of convolutional operations. However, current noise generation models merely relies on the information from the pixel space, which increases the difficulty to approach the target distribution. Fortunately, the long proven wavelet transformation is able to decompose multiple spectral information from the images. In this work, we propose a novel multi-channel wavelet-based filtering method for GANs, to cope with this problem. When embedding a wavelet deconvolution layer in the generator, the resultant GAN, called WaveletGAN, takes advantage of the wavelet deconvolution to learn a filtering with multiple channels, which can efficiently homogenize the generated noise via an averaging operation, so as to generate high-fidelity samples. We conducted benchmark experiments on the Fashion-MNIST, KMNIST and SVHN datasets through an open GAN benchmark tool. The results show that WaveletGAN has excellent performance in generating high-fidelity samples, thanks to the smallest FIDs obtained on these datasets.
Two-stage Image Classification Supervised by a Single Teacher Single Student Model
Sep 26, 2019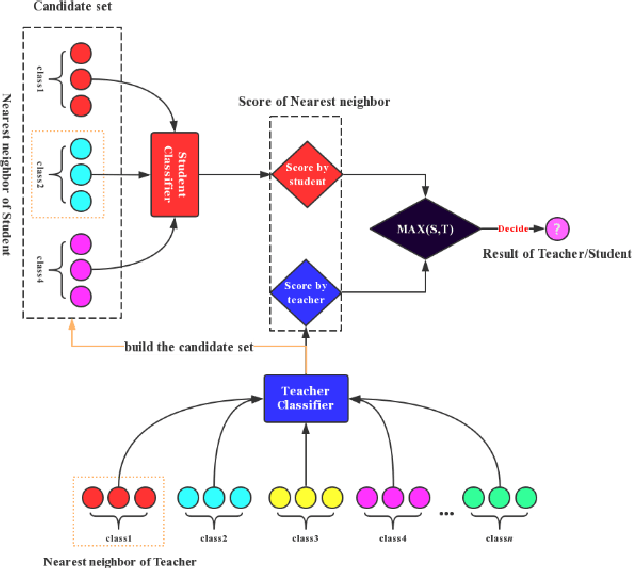

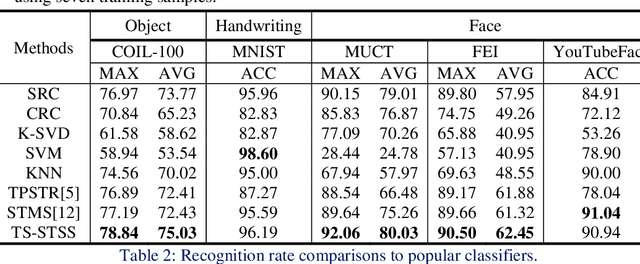
The two-stage strategy has been widely used in image classification. However, these methods barely take the classification criteria of the first stage into consideration in the second prediction stage. In this paper, we propose a novel two-stage representation method (TSR), and convert it to a Single-Teacher Single-Student (STSS) problem in our two-stage image classification framework. We seek the nearest neighbours of the test sample to choose candidate target classes. Meanwhile, the first stage classifier is formulated as the teacher, which holds the classification scores. The samples of the candidate classes are utilized to learn a student classifier based on L2-minimization in the second stage. The student will be supervised by the teacher classifier, which approves the student only if it obtains a higher score. In actuality, the proposed framework generates a stronger classifier by staging two weaker classifiers in a novel way. The experiments conducted on several face and object databases show that our proposed framework is effective and outperforms multiple popular classification methods.
Deep Collaborative Weight-based Classification
Feb 21, 2018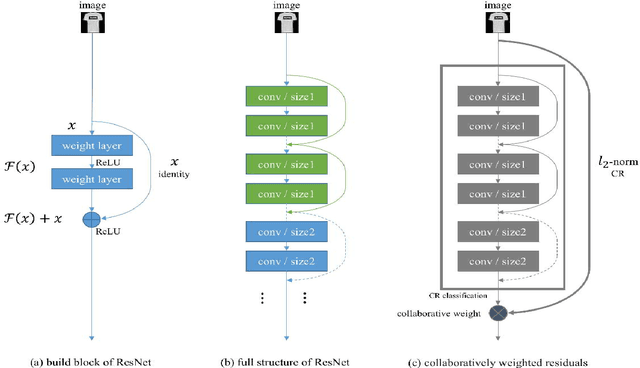
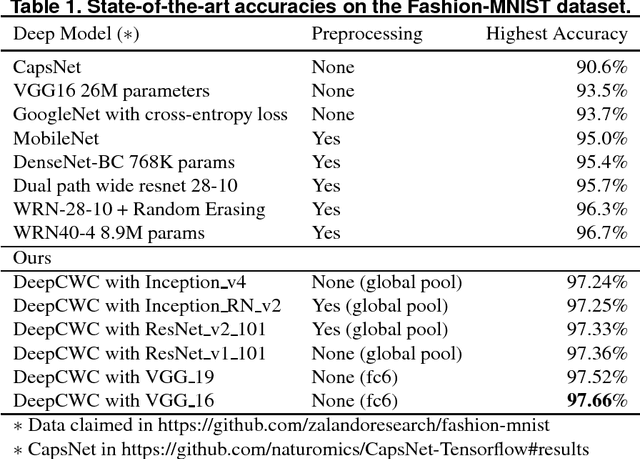
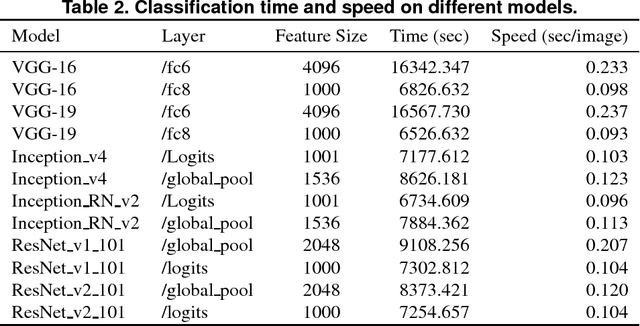
One of the biggest problems in deep learning is its difficulty to retain consistent robustness when transferring the model trained on one dataset to another dataset. To conquer the problem, deep transfer learning was implemented to execute various vision tasks by using a pre-trained deep model in a diverse dataset. However, the robustness was often far from state-of-the-art. We propose a collaborative weight-based classification method for deep transfer learning (DeepCWC). The method performs the L2-norm based collaborative representation on the original images, as well as the deep features extracted by pre-trained deep models. Two distance vectors will be obtained based on the two representation coefficients, and then fused together via the collaborative weight. The two feature sets show a complementary character, and the original images provide information compensating the missed part in the transferred deep model. A series of experiments conducted on both small and large vision datasets demonstrated the robustness of the proposed DeepCWC in both face recognition and object recognition tasks.