 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation: A Survey
Paper and Code
Jun 30, 2020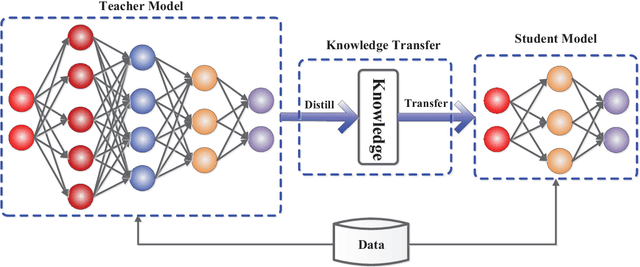
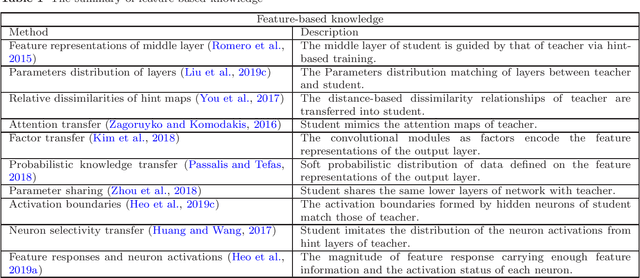
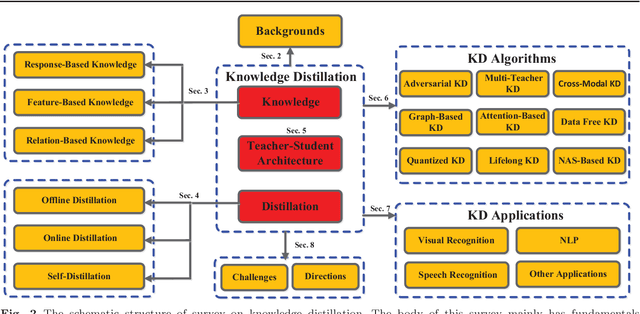
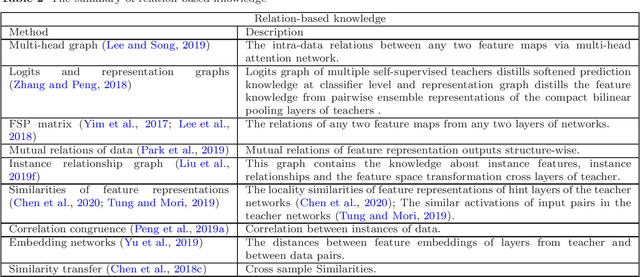
In recent years, deep neural networks have been successful in both industry and academia, especially for computer vision tasks. The great success of deep learning is mainly due to its scalability to encode large-scale data and to maneuver billions of model parameters. However, it is a challenge to deploy these cumbersome deep models on devices with limited resources, e.g., mobile phones and embedded devices, not only because of the high computational complexity but also the large storage requirements. To this end, a variety of model compression and acceleration techniques have been developed. As a representative type of model compression and acceleration, knowledge distillation effectively learns a small student model from a large teacher model. It has received rapid increasing attention from the community. This paper provides a comprehensive survey of knowledge distillation from the perspectives of knowledge categories, training schemes, distillation algorithms and applications. Furthermore, challenges in knowledge distillation are briefly reviewed and comments on future research are discussed and forwarded.