 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Actions Succeed, Bad Actions Generalize: A Case Study on Why RL Generalizes Better
Paper and Code
Mar 19, 2025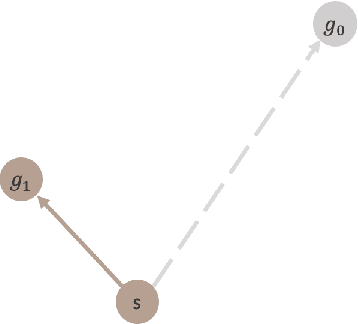
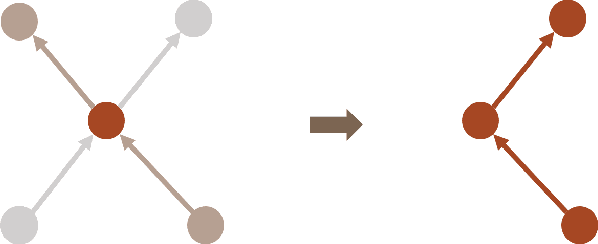
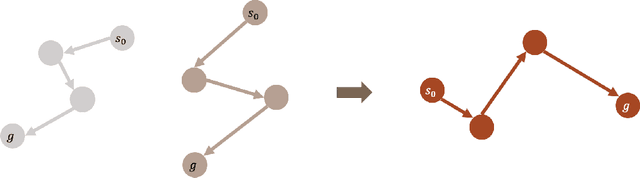
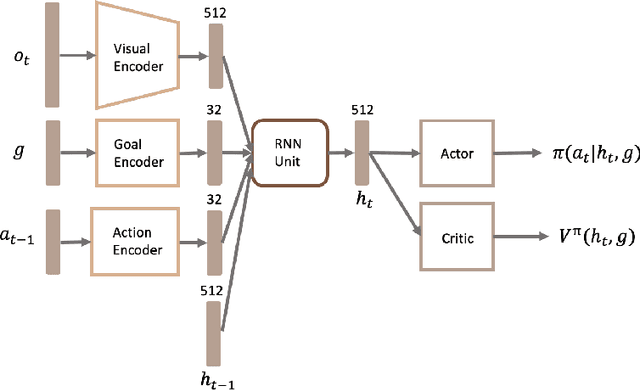
Supervised learning (SL) and reinforcement learning (RL) are both widely used to train general-purpose agents for complex tasks, yet their generalization capabilities and underlying mechanisms are not yet fully understood. In this paper, we provide a direct comparison between SL and RL in terms of zero-shot generalization. Using the Habitat visual navigation task as a testbed, we evaluate Proximal Policy Optimization (PPO) and Behavior Cloning (BC) agents across two levels of generalization: state-goal pair generalization within seen environments and generalization to unseen environments. Our experiments show that PPO consistently outperforms BC across both zero-shot settings and performance metrics-success rate and SPL. Interestingly, even though additional optimal training data enables BC to match PPO's zero-shot performance in SPL, it still falls significantly behind in success rate. We attribute this to a fundamental difference in how models trained by these algorithms generalize: BC-trained models generalize by imitating successful trajectories, whereas TD-based RL-trained models generalize through combinatorial experience stitching-leveraging fragments of past trajectories (mostly failed ones) to construct solutions for new tasks. This allows RL to efficiently find solutions in vast state space and discover novel strategies beyond the scope of human knowledge. Besides providing empirical evidence and understanding, we also propose practical guidelines for improving the generalization capabilities of RL and SL through algorithm design.