 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGSAC: Density Guided Sampling and Consensus
Paper and Code
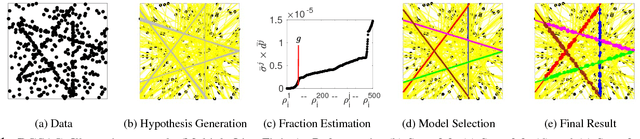
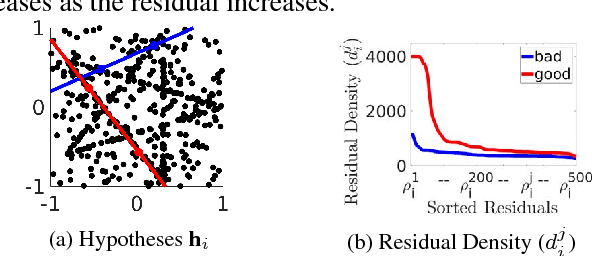
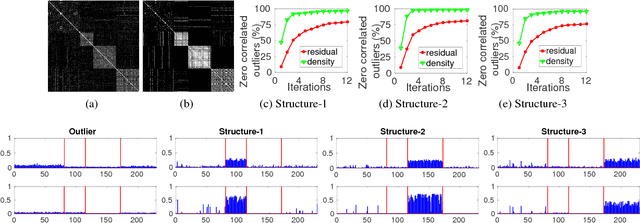
Robust multiple model fitting plays a crucial role in many computer vision applications. Unlike single model fitting problems, the multi-model fitting has additional challenges. The unknown number of models and the inlier noise scale are the two most important of them, which are in general provided by the user using ground-truth or some other auxiliary information. Mode seeking/ clustering-based approaches crucially depend on the quality of model hypotheses generated. While preference analysis based guided sampling approaches have shown remarkable performance, they operate in a time budget framework, and the user provides the time as a reasonable guess. In this paper, we deviate from the mode seeking and time budget framework. We propose a concept called Kernel Residual Density (KRD) and apply it to various components of a multiple-model fitting pipeline. The Kernel Residual Density act as a key differentiator between inliers and outliers. We use KRD to guide and automatically stop the sampling process. The sampling process stops after generating a set of hypotheses that can explain all the data points. An explanation score is maintained for each data point, which is updated on-the-fly. We propose two model selection algorithms, an optimal quadratic program based, and a greedy. Unlike mode seeking approaches, our model selection algorithms seek to find one representative hypothesis for each genuine structure present in the data. We evaluate our method (dubbed as DGSAC) on a wide variety of tasks like planar segmentation, motion segmentation, vanishing point estimation, plane fitting to 3D point cloud, line, and circle fitting, which shows the effectiveness of our method and its unified nature.