 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Syntactic and Semantic Proximity on Machine Translation with Back-Translation
Paper and Code
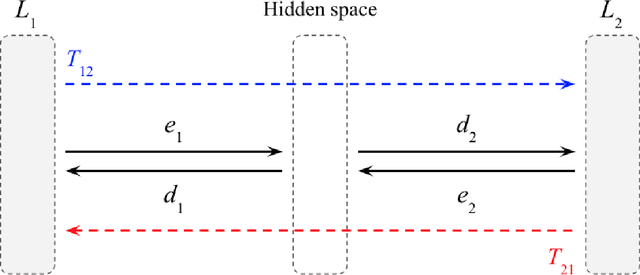

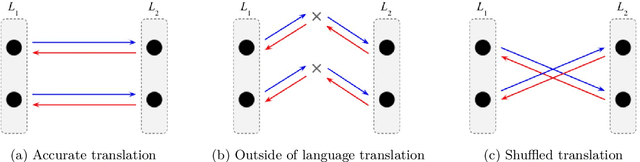

Unsupervised on-the-fly back-translation, in conjunction with multilingual pretraining, is the dominant method for unsupervised neural machine translation. Theoretically, however, the method should not work in general. We therefore conduct controlled experiments with artificial languages to determine what properties of languages make back-translation an effective training method, covering lexical, syntactic, and semantic properties. We find, contrary to popular belief, that (i) parallel word frequency distributions, (ii) partially shared vocabulary, and (iii) similar syntactic structure across languages are not sufficient to explain the success of back-translation. We show however that even crude semantic signal (similar lexical fields across languages) does improve alignment of two languages through back-translation. We conjecture that rich semantic dependencies, parallel across languages, are at the root of the success of unsupervised methods based on back-translation. Overall, the success of unsupervised machine translation was far from being analytically guaranteed. Instead, it is another proof that languages of the world share deep similarities, and we hope to show how to identify which of these similarities can serve the development of unsupervised, cross-linguistic tools.