 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing for Understanding of English Verb Classes and Alternations in Large Pre-trained Language Models
Sep 11, 2022
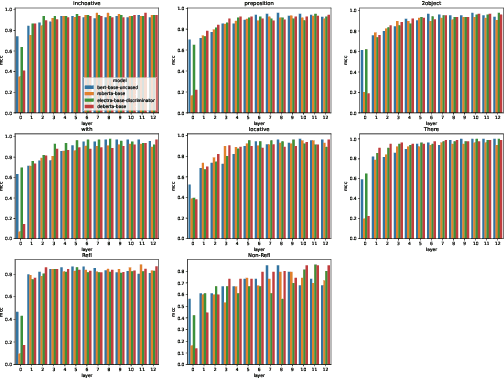
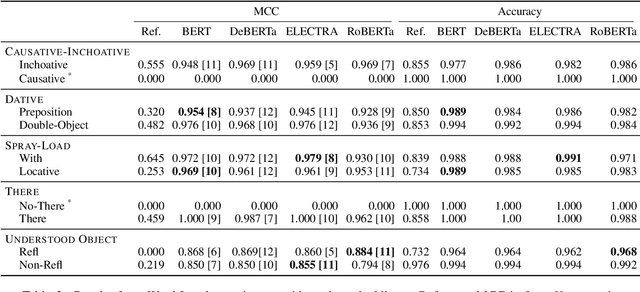
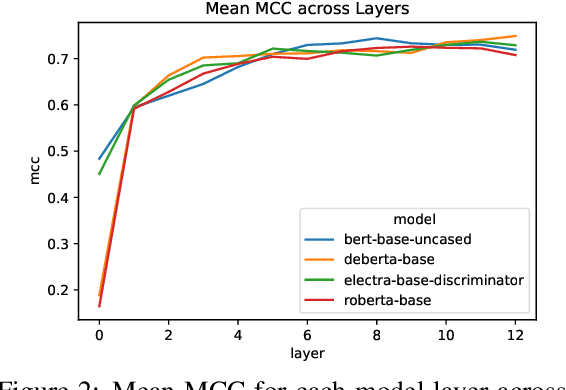
We investigate the extent to which verb alternation classes, as described by Levin (1993), are encoded in the embeddings of Large Pre-trained Language Models (PLMs) such as BERT, RoBERTa, ELECTRA, and DeBERTa using selectively constructed diagnostic classifiers for word and sentence-level prediction tasks. We follow and expand upon the experiments of Kann et al. (2019), which aim to probe whether static embeddings encode frame-selectional properties of verbs. At both the word and sentence level, we find that contextual embeddings from PLMs not only outperform non-contextual embeddings, but achieve astonishingly high accuracies on tasks across most alternation classes. Additionally, we find evidence that the middle-to-upper layers of PLMs achieve better performance on average than the lower layers across all probing tasks.