 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccSim: Multi-kilometer Simulation with Long-horizon Occupancy World Models
Mar 30, 2026Data-driven autonomous driving simulation has long been constrained by its heavy reliance on pre-recorded driving logs or spatial priors, such as HD maps. This fundamental dependency severely limits scalability, restricting open-ended generation capabilities to the finite scale of existing collected datasets. To break this bottleneck, we present OccSim, the first occupancy world model-driven 3D simulator. OccSim obviates the requirement for continuous logs or HD maps; conditioned only on a single initial frame and a sequence of future ego-actions, it can stably generate over 3,000 continuous frames, enabling the continuous construction of large-scale 3D occupancy maps spanning over 4 kilometers for simulation. This represents an >80x improvement in stable generation length over previous state-of-the-art occupancy world models. OccSim is powered by two modules: W-DiT based static occupancy world model and the Layout Generator. W-DiT handles the ultra-long-horizon generation of static environments by explicitly introducing known rigid transformations in architecture design, while the Layout Generator populates the dynamic foreground with reactive agents based on the synthesized road topology. With these designs, OccSim can synthesize massive, diverse simulation streams. Extensive experiments demonstrate its downstream utility: data collected directly from OccSim can pre-train 4D semantic occupancy forecasting models to achieve up to 67% zero-shot performance on unseen data, outperforming previous asset-based simulator by 11%. When scaling the OccSim dataset to 5x the size, the zero-shot performance increases to about 74%, while the improvement over asset-based simulators expands to 22.1%.
AutoWorld: Scaling Multi-Agent Traffic Simulation with Self-Supervised World Models
Mar 30, 2026Multi-agent traffic simulation is central to developing and testing autonomous driving systems. Recent data-driven simulators have achieved promising results, but rely heavily on supervised learning from labeled trajectories or semantic annotations, making it costly to scale their performance. Meanwhile, large amounts of unlabeled sensor data can be collected at scale but remain largely unused by existing traffic simulation frameworks. This raises a key question: How can a method harness unlabeled data to improve traffic simulation performance? In this work, we propose AutoWorld, a traffic simulation framework that employs a world model learned from unlabeled occupancy representations of LiDAR data. Given world model samples, AutoWorld constructs a coarse-to-fine predictive scene context as input to a multi-agent motion generation model. To promote sample diversity, AutoWorld uses a cascaded Determinantal Point Process framework to guide the sampling processes of both the world model and the motion model. Furthermore, we designed a motion-aware latent supervision objective that enhances AutoWorld's representation of scene dynamics. Experiments on the WOSAC benchmark show that AutoWorld ranks first on the leaderboard according to the primary Realism Meta Metric (RMM). We further show that simulation performance consistently improves with the inclusion of unlabeled LiDAR data, and study the efficacy of each component with ablations. Our method paves the way for scaling traffic simulation realism without additional labeling. Our project page contains additional visualizations and released code.
FSMDet: Vision-guided feature diffusion for fully sparse 3D detector
Sep 11, 2024Fully sparse 3D detection has attracted an increasing interest in the recent years. However, the sparsity of the features in these frameworks challenges the generation of proposals because of the limited diffusion process. In addition, the quest for efficiency has led to only few work on vision-assisted fully sparse models. In this paper, we propose FSMDet (Fully Sparse Multi-modal Detection), which use visual information to guide the LiDAR feature diffusion process while still maintaining the efficiency of the pipeline. Specifically, most of fully sparse works focus on complex customized center fusion diffusion/regression operators. However, we observed that if the adequate object completion is performed, even the simplest interpolation operator leads to satisfactory results. Inspired by this observation, we split the vision-guided diffusion process into two modules: a Shape Recover Layer (SRLayer) and a Self Diffusion Layer (SDLayer). The former uses RGB information to recover the shape of the visible part of an object, and the latter uses a visual prior to further spread the features to the center region. Experiments demonstrate that our approach successfully improves the performance of previous fully sparse models that use LiDAR only and reaches SOTA performance in multimodal models. At the same time, thanks to the sparse architecture, our method can be up to 5 times more efficient than previous SOTA methods in the inference process.
What You See Is What You Detect: Towards better Object Densification in 3D detection
Oct 27, 2023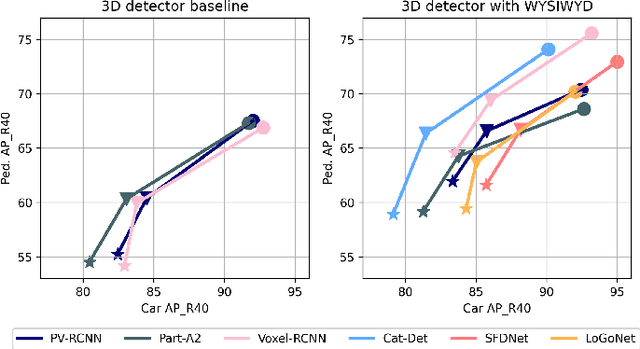
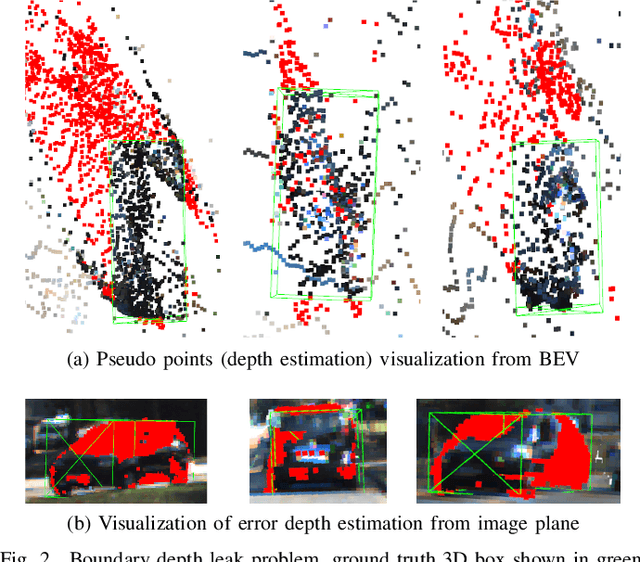

Recent works have demonstrated the importance of object completion in 3D Perception from Lidar signal. Several methods have been proposed in which modules were used to densify the point clouds produced by laser scanners, leading to better recall and more accurate results. Pursuing in that direction, we present, in this work, a counter-intuitive perspective: the widely-used full-shape completion approach actually leads to a higher error-upper bound especially for far away objects and small objects like pedestrians. Based on this observation, we introduce a visible part completion method that requires only 11.3\% of the prediction points that previous methods generate. To recover the dense representation, we propose a mesh-deformation-based method to augment the point set associated with visible foreground objects. Considering that our approach focuses only on the visible part of the foreground objects to achieve accurate 3D detection, we named our method What You See Is What You Detect (WYSIWYD). Our proposed method is thus a detector-independent model that consists of 2 parts: an Intra-Frustum Segmentation Transformer (IFST) and a Mesh Depth Completion Network(MDCNet) that predicts the foreground depth from mesh deformation. This way, our model does not require the time-consuming full-depth completion task used by most pseudo-lidar-based methods. Our experimental evaluation shows that our approach can provide up to 12.2\% performance improvements over most of the public baseline models on the KITTI and NuScenes dataset bringing the state-of-the-art to a new level. The codes will be available at \textcolor[RGB]{0,0,255}{\url{{https://github.com/Orbis36/WYSIWYD}}
Testing Pre-trained Language Models' Understanding of Distributivity via Causal Mediation Analysis
Sep 11, 2022
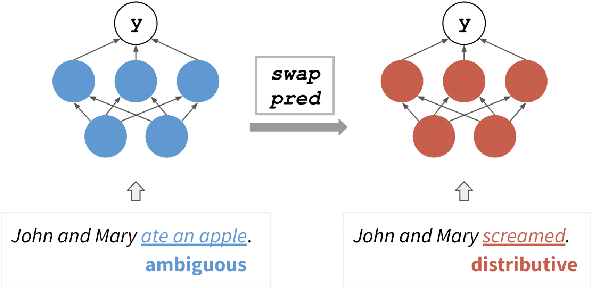
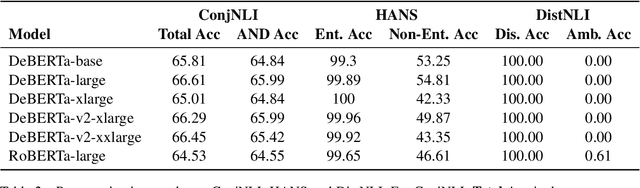
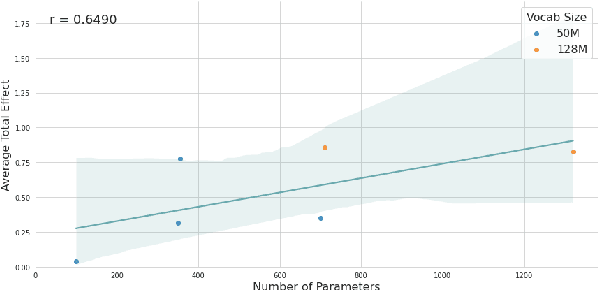
To what extent do pre-trained language models grasp semantic knowledge regarding the phenomenon of distributivity? In this paper, we introduce DistNLI, a new diagnostic dataset for natural language inference that targets the semantic difference arising from distributivity, and employ the causal mediation analysis framework to quantify the model behavior and explore the underlying mechanism in this semantically-related task. We find that the extent of models' understanding is associated with model size and vocabulary size. We also provide insights into how models encode such high-level semantic knowledge.