 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Thermal MOT: A Novel Box Association Method Leveraging Thermal Identity and Motion Similarity
Nov 20, 2024Multiple Object Tracking (MOT) in thermal imaging presents unique challenges due to the lack of visual features and the complexity of motion patterns. This paper introduces an innovative approach to improve MOT in the thermal domain by developing a novel box association method that utilizes both thermal object identity and motion similarity. Our method merges thermal feature sparsity and dynamic object tracking, enabling more accurate and robust MOT performance. Additionally, we present a new dataset comprised of a large-scale collection of thermal and RGB images captured in diverse urban environments, serving as both a benchmark for our method and a new resource for thermal imaging. We conduct extensive experiments to demonstrate the superiority of our approach over existing methods, showing significant improvements in tracking accuracy and robustness under various conditions. Our findings suggest that incorporating thermal identity with motion data enhances MOT performance. The newly collected dataset and source code is available at https://github.com/wassimea/thermalMOT
FSMDet: Vision-guided feature diffusion for fully sparse 3D detector
Sep 11, 2024Fully sparse 3D detection has attracted an increasing interest in the recent years. However, the sparsity of the features in these frameworks challenges the generation of proposals because of the limited diffusion process. In addition, the quest for efficiency has led to only few work on vision-assisted fully sparse models. In this paper, we propose FSMDet (Fully Sparse Multi-modal Detection), which use visual information to guide the LiDAR feature diffusion process while still maintaining the efficiency of the pipeline. Specifically, most of fully sparse works focus on complex customized center fusion diffusion/regression operators. However, we observed that if the adequate object completion is performed, even the simplest interpolation operator leads to satisfactory results. Inspired by this observation, we split the vision-guided diffusion process into two modules: a Shape Recover Layer (SRLayer) and a Self Diffusion Layer (SDLayer). The former uses RGB information to recover the shape of the visible part of an object, and the latter uses a visual prior to further spread the features to the center region. Experiments demonstrate that our approach successfully improves the performance of previous fully sparse models that use LiDAR only and reaches SOTA performance in multimodal models. At the same time, thanks to the sparse architecture, our method can be up to 5 times more efficient than previous SOTA methods in the inference process.
What You See Is What You Detect: Towards better Object Densification in 3D detection
Oct 27, 2023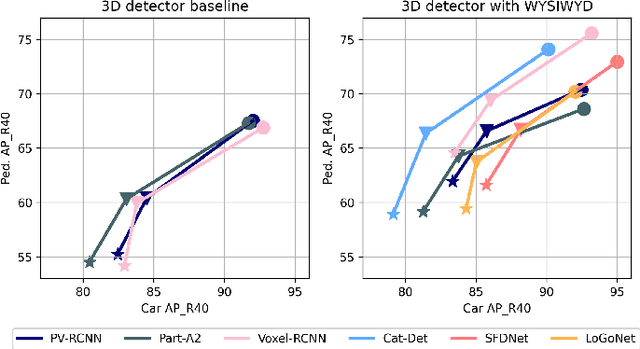
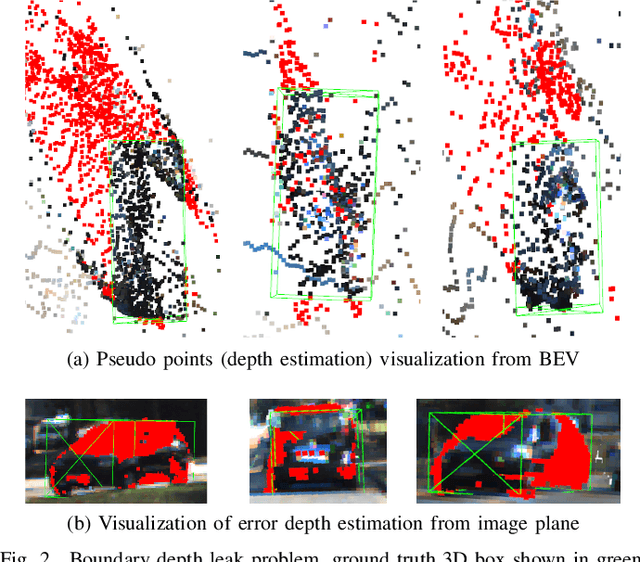
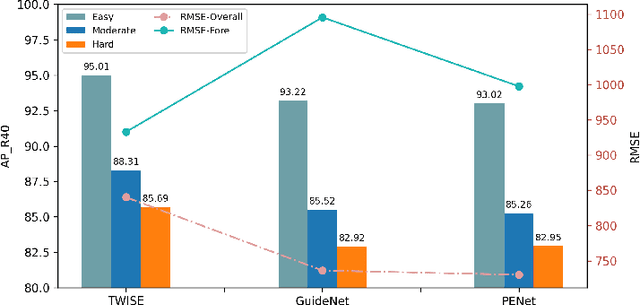

Recent works have demonstrated the importance of object completion in 3D Perception from Lidar signal. Several methods have been proposed in which modules were used to densify the point clouds produced by laser scanners, leading to better recall and more accurate results. Pursuing in that direction, we present, in this work, a counter-intuitive perspective: the widely-used full-shape completion approach actually leads to a higher error-upper bound especially for far away objects and small objects like pedestrians. Based on this observation, we introduce a visible part completion method that requires only 11.3\% of the prediction points that previous methods generate. To recover the dense representation, we propose a mesh-deformation-based method to augment the point set associated with visible foreground objects. Considering that our approach focuses only on the visible part of the foreground objects to achieve accurate 3D detection, we named our method What You See Is What You Detect (WYSIWYD). Our proposed method is thus a detector-independent model that consists of 2 parts: an Intra-Frustum Segmentation Transformer (IFST) and a Mesh Depth Completion Network(MDCNet) that predicts the foreground depth from mesh deformation. This way, our model does not require the time-consuming full-depth completion task used by most pseudo-lidar-based methods. Our experimental evaluation shows that our approach can provide up to 12.2\% performance improvements over most of the public baseline models on the KITTI and NuScenes dataset bringing the state-of-the-art to a new level. The codes will be available at \textcolor[RGB]{0,0,255}{\url{{https://github.com/Orbis36/WYSIWYD}}
T-FFTRadNet: Object Detection with Swin Vision Transformers from Raw ADC Radar Signals
Mar 29, 2023



Object detection utilizing Frequency Modulated Continous Wave radar is becoming increasingly popular in the field of autonomous systems. Radar does not possess the same drawbacks seen by other emission-based sensors such as LiDAR, primarily the degradation or loss of return signals due to weather conditions such as rain or snow. However, radar does possess traits that make it unsuitable for standard emission-based deep learning representations such as point clouds. Radar point clouds tend to be sparse and therefore information extraction is not efficient. To overcome this, more traditional digital signal processing pipelines were adapted to form inputs residing directly in the frequency domain via Fast Fourier Transforms. Commonly, three transformations were used to form Range-Azimuth-Doppler cubes in which deep learning algorithms could perform object detection. This too has drawbacks, namely the pre-processing costs associated with performing multiple Fourier Transforms and normalization. We explore the possibility of operating on raw radar inputs from analog to digital converters via the utilization of complex transformation layers. Moreover, we introduce hierarchical Swin Vision transformers to the field of radar object detection and show their capability to operate on inputs varying in pre-processing, along with different radar configurations, i.e. relatively low and high numbers of transmitters and receivers, while obtaining on par or better results than the state-of-the-art.
RADDet: Range-Azimuth-Doppler based Radar Object Detection for Dynamic Road Users
May 02, 2021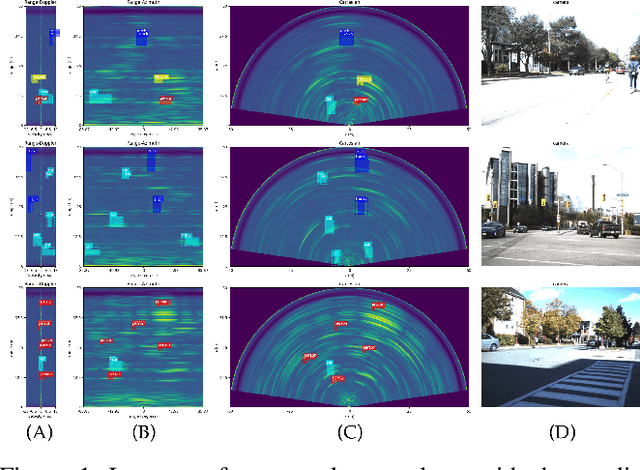
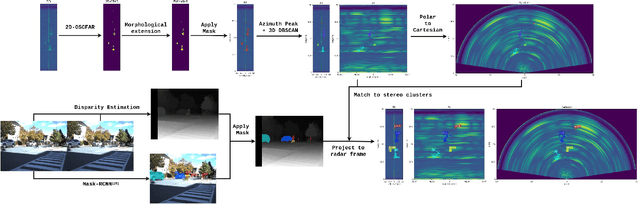
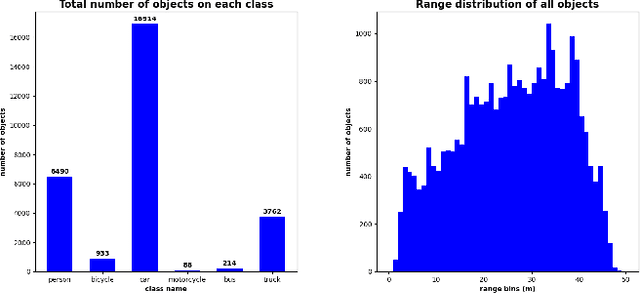
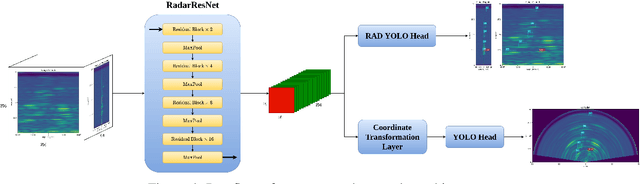
Object detection using automotive radars has not been explored with deep learning models in comparison to the camera based approaches. This can be attributed to the lack of public radar datasets. In this paper, we collect a novel radar dataset that contains radar data in the form of Range-Azimuth-Doppler tensors along with the bounding boxes on the tensor for dynamic road users, category labels, and 2D bounding boxes on the Cartesian Bird-Eye-View range map. To build the dataset, we propose an instance-wise auto-annotation method. Furthermore, a novel Range-Azimuth-Doppler based multi-class object detection deep learning model is proposed. The algorithm is a one-stage anchor-based detector that generates both 3D bounding boxes and 2D bounding boxes on Range-Azimuth-Doppler and Cartesian domains, respectively. Our proposed algorithm achieves 56.3% AP with IOU of 0.3 on 3D bounding box predictions, and 51.6% with IOU of 0.5 on 2D bounding box prediction. Our dataset and the code can be found at https://github.com/ZhangAoCanada/RADDet.git.
Point Cloud based Hierarchical Deep Odometry Estimation
Mar 05, 2021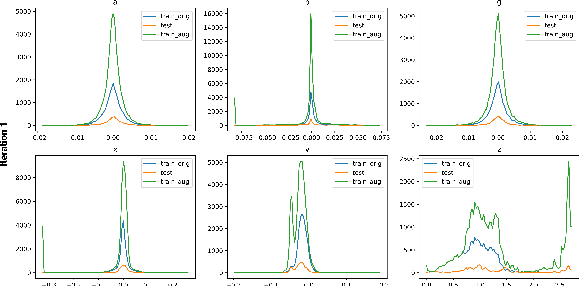
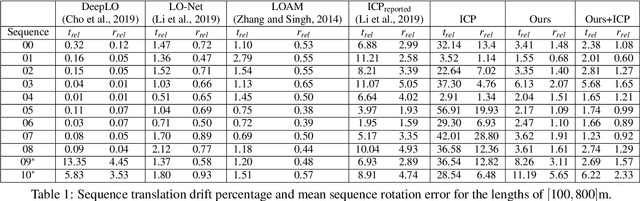
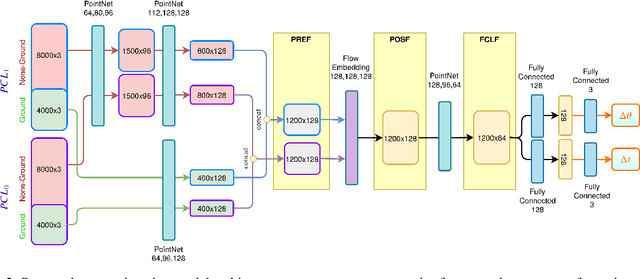
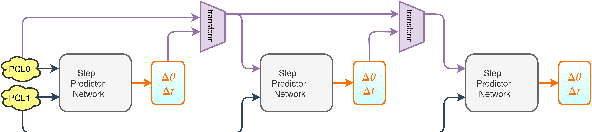
Processing point clouds using deep neural networks is still a challenging task. Most existing models focus on object detection and registration with deep neural networks using point clouds. In this paper, we propose a deep model that learns to estimate odometry in driving scenarios using point cloud data. The proposed model consumes raw point clouds in order to extract frame-to-frame odometry estimation through a hierarchical model architecture. Also, a local bundle adjustment variation of this model using LSTM layers is implemented. These two approaches are comprehensively evaluated and are compared against the state-of-the-art.
PolarNet: Accelerated Deep Open Space Segmentation Using Automotive Radar in Polar Domain
Mar 04, 2021
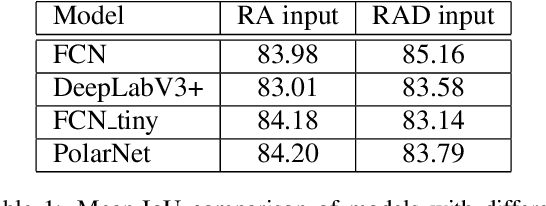
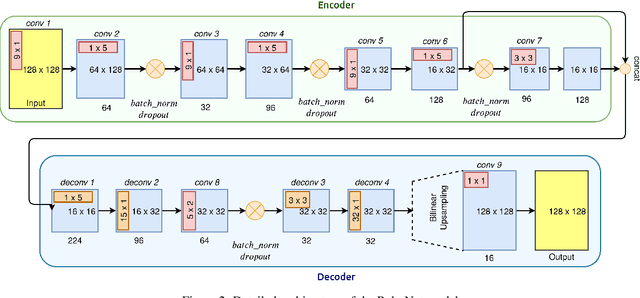
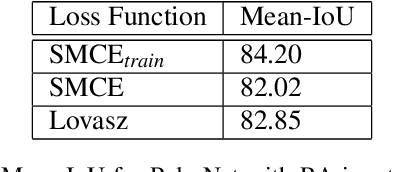
Camera and Lidar processing have been revolutionized with the rapid development of deep learning model architectures. Automotive radar is one of the crucial elements of automated driver assistance and autonomous driving systems. Radar still relies on traditional signal processing techniques, unlike camera and Lidar based methods. We believe this is the missing link to achieve the most robust perception system. Identifying drivable space and occupied space is the first step in any autonomous decision making task. Occupancy grid map representation of the environment is often used for this purpose. In this paper, we propose PolarNet, a deep neural model to process radar information in polar domain for open space segmentation. We explore various input-output representations. Our experiments show that PolarNet is a effective way to process radar data that achieves state-of-the-art performance and processing speeds while maintaining a compact size.
Deep Open Space Segmentation using Automotive Radar
Mar 18, 2020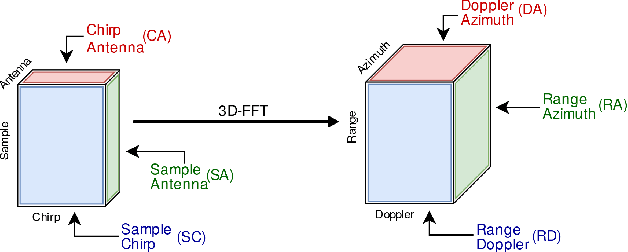
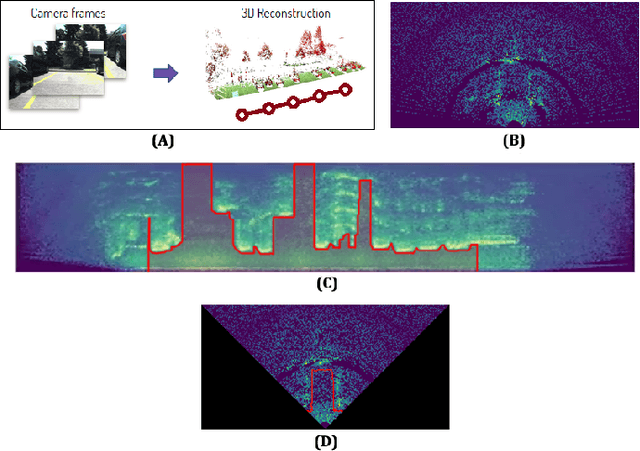
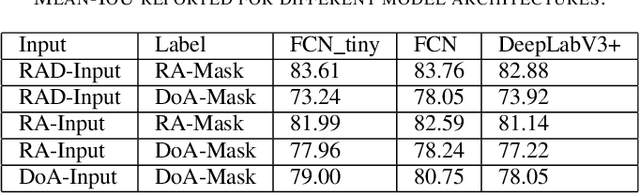
In this work, we propose the use of radar with advanced deep segmentation models to identify open space in parking scenarios. A publically available dataset of radar observations called SCORP was collected. Deep models are evaluated with various radar input representations. Our proposed approach achieves low memory usage and real-time processing speeds, and is thus very well suited for embedded deployment.
How much real data do we actually need: Analyzing object detection performance using synthetic and real data
Jul 16, 2019
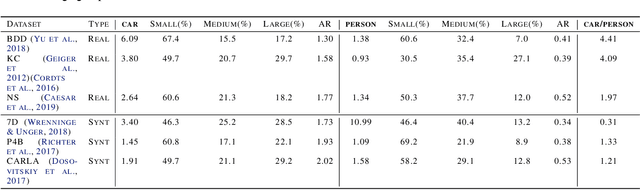

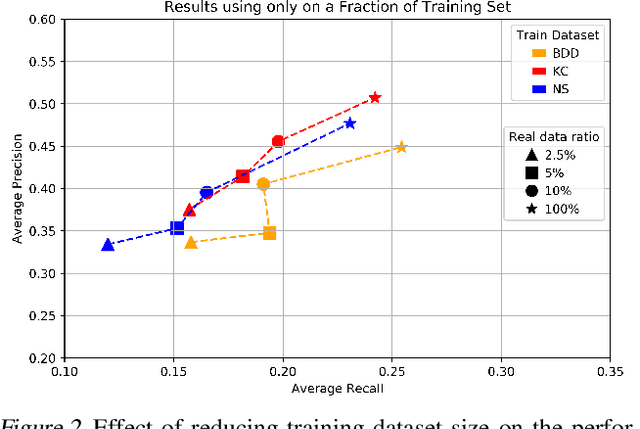
In recent years, deep learning models have resulted in a huge amount of progress in various areas, including computer vision. By nature, the supervised training of deep models requires a large amount of data to be available. This ideal case is usually not tractable as the data annotation is a tremendously exhausting and costly task to perform. An alternative is to use synthetic data. In this paper, we take a comprehensive look into the effects of replacing real data with synthetic data. We further analyze the effects of having a limited amount of real data. We use multiple synthetic and real datasets along with a simulation tool to create large amounts of cheaply annotated synthetic data. We analyze the domain similarity of each of these datasets. We provide insights about designing a methodological procedure for training deep networks using these datasets.
Multi-scale prediction for robust hand detection and classification
Apr 23, 2018


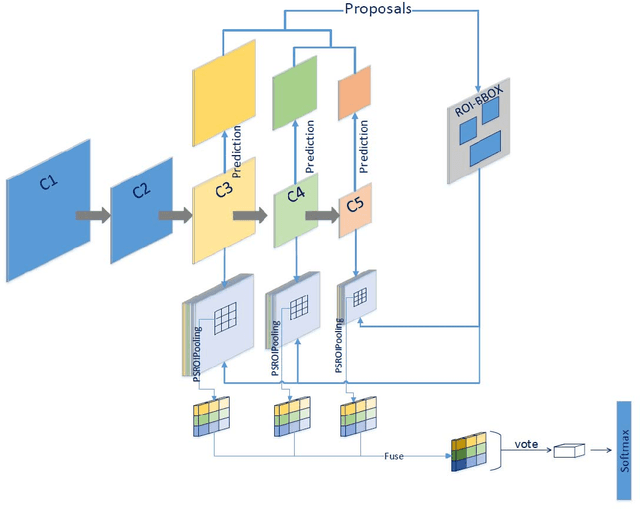
In this paper, we present a multi-scale Fully Convolutional Networks (MSP-RFCN) to robustly detect and classify human hands under various challenging conditions. In our approach, the input image is passed through the proposed network to generate score maps, based on multi-scale predictions. The network has been specifically designed to deal with small objects. It uses an architecture based on region proposals generated at multiple scales. Our method is evaluated on challenging hand datasets, namely the Vision for Intelligent Vehicles and Applications (VIVA) Challenge and the Oxford hand dataset. It is compared against recent hand detection algorithms. The experimental results demonstrate that our proposed method achieves state-of-the-art detection for hands of various sizes.