 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You See Is What You Detect: Towards better Object Densification in 3D detection
Oct 27, 2023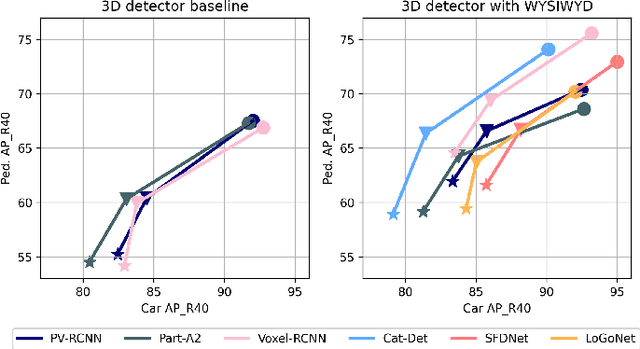
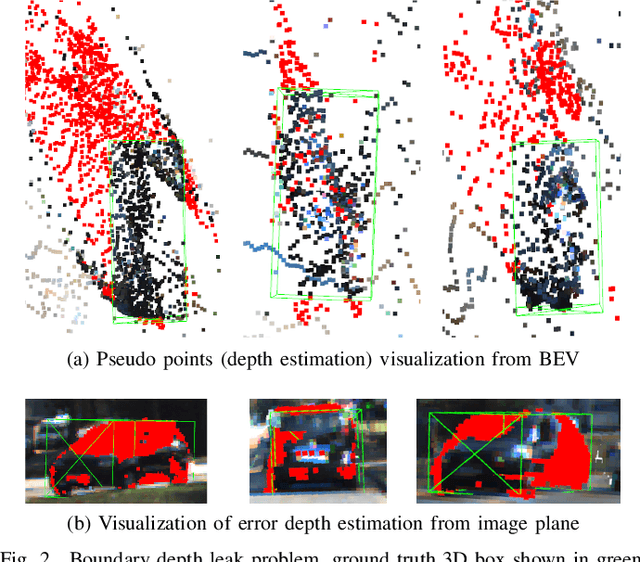
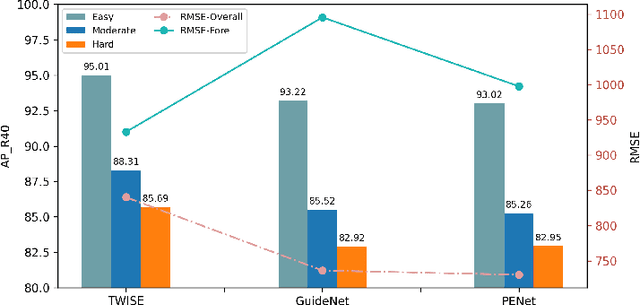

Recent works have demonstrated the importance of object completion in 3D Perception from Lidar signal. Several methods have been proposed in which modules were used to densify the point clouds produced by laser scanners, leading to better recall and more accurate results. Pursuing in that direction, we present, in this work, a counter-intuitive perspective: the widely-used full-shape completion approach actually leads to a higher error-upper bound especially for far away objects and small objects like pedestrians. Based on this observation, we introduce a visible part completion method that requires only 11.3\% of the prediction points that previous methods generate. To recover the dense representation, we propose a mesh-deformation-based method to augment the point set associated with visible foreground objects. Considering that our approach focuses only on the visible part of the foreground objects to achieve accurate 3D detection, we named our method What You See Is What You Detect (WYSIWYD). Our proposed method is thus a detector-independent model that consists of 2 parts: an Intra-Frustum Segmentation Transformer (IFST) and a Mesh Depth Completion Network(MDCNet) that predicts the foreground depth from mesh deformation. This way, our model does not require the time-consuming full-depth completion task used by most pseudo-lidar-based methods. Our experimental evaluation shows that our approach can provide up to 12.2\% performance improvements over most of the public baseline models on the KITTI and NuScenes dataset bringing the state-of-the-art to a new level. The codes will be available at \textcolor[RGB]{0,0,255}{\url{{https://github.com/Orbis36/WYSIWYD}}