 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Thermal MOT: A Novel Box Association Method Leveraging Thermal Identity and Motion Similarity
Nov 20, 2024Multiple Object Tracking (MOT) in thermal imaging presents unique challenges due to the lack of visual features and the complexity of motion patterns. This paper introduces an innovative approach to improve MOT in the thermal domain by developing a novel box association method that utilizes both thermal object identity and motion similarity. Our method merges thermal feature sparsity and dynamic object tracking, enabling more accurate and robust MOT performance. Additionally, we present a new dataset comprised of a large-scale collection of thermal and RGB images captured in diverse urban environments, serving as both a benchmark for our method and a new resource for thermal imaging. We conduct extensive experiments to demonstrate the superiority of our approach over existing methods, showing significant improvements in tracking accuracy and robustness under various conditions. Our findings suggest that incorporating thermal identity with motion data enhances MOT performance. The newly collected dataset and source code is available at https://github.com/wassimea/thermalMOT
Point Cloud based Hierarchical Deep Odometry Estimation
Mar 05, 2021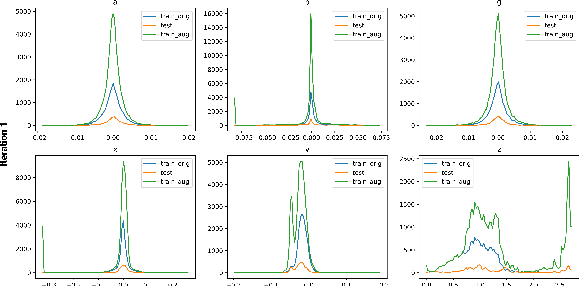
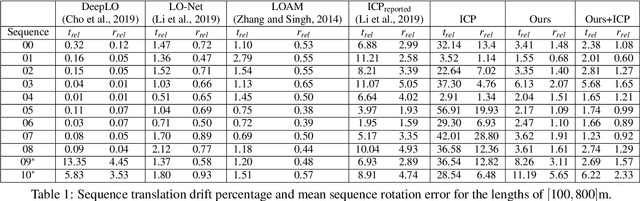
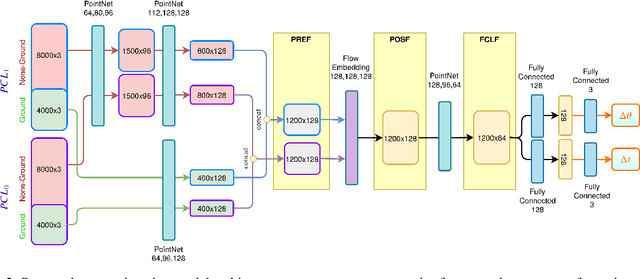
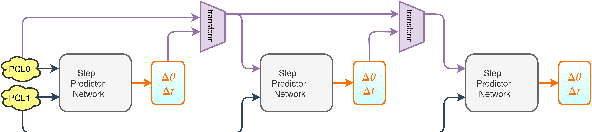
Processing point clouds using deep neural networks is still a challenging task. Most existing models focus on object detection and registration with deep neural networks using point clouds. In this paper, we propose a deep model that learns to estimate odometry in driving scenarios using point cloud data. The proposed model consumes raw point clouds in order to extract frame-to-frame odometry estimation through a hierarchical model architecture. Also, a local bundle adjustment variation of this model using LSTM layers is implemented. These two approaches are comprehensively evaluated and are compared against the state-of-the-art.
PolarNet: Accelerated Deep Open Space Segmentation Using Automotive Radar in Polar Domain
Mar 04, 2021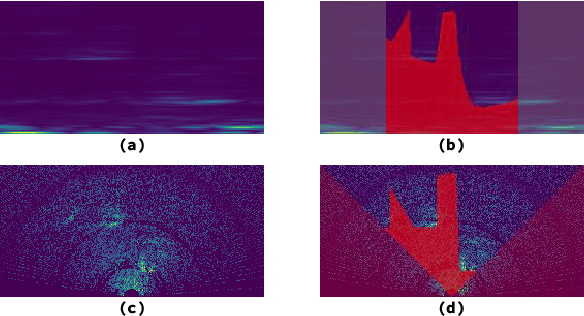
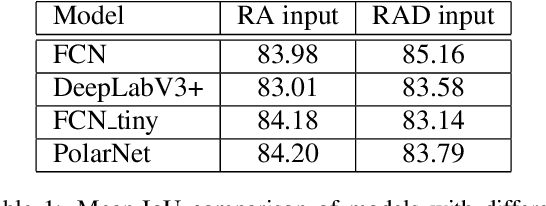
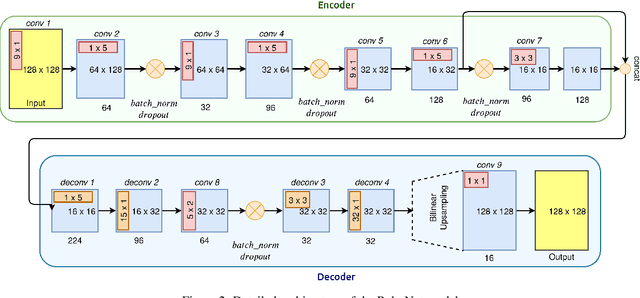
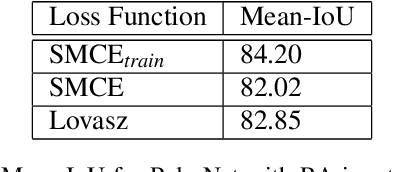
Camera and Lidar processing have been revolutionized with the rapid development of deep learning model architectures. Automotive radar is one of the crucial elements of automated driver assistance and autonomous driving systems. Radar still relies on traditional signal processing techniques, unlike camera and Lidar based methods. We believe this is the missing link to achieve the most robust perception system. Identifying drivable space and occupied space is the first step in any autonomous decision making task. Occupancy grid map representation of the environment is often used for this purpose. In this paper, we propose PolarNet, a deep neural model to process radar information in polar domain for open space segmentation. We explore various input-output representations. Our experiments show that PolarNet is a effective way to process radar data that achieves state-of-the-art performance and processing speeds while maintaining a compact size.
Deep Open Space Segmentation using Automotive Radar
Mar 18, 2020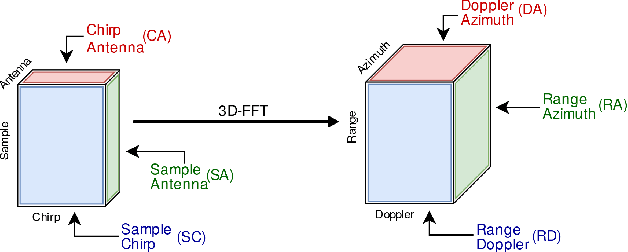
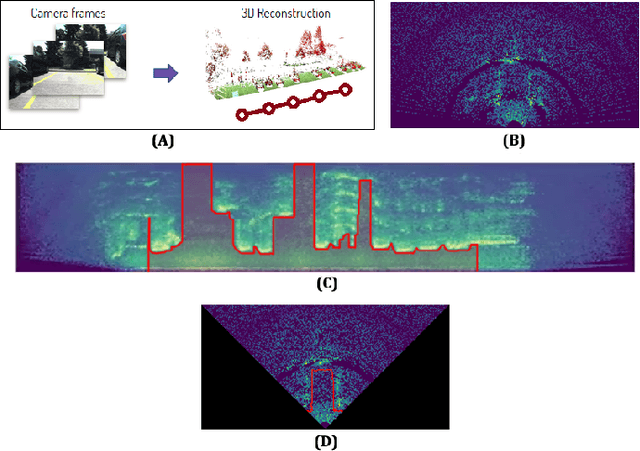
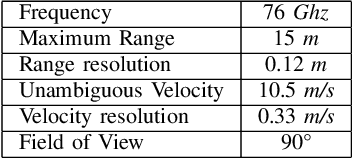
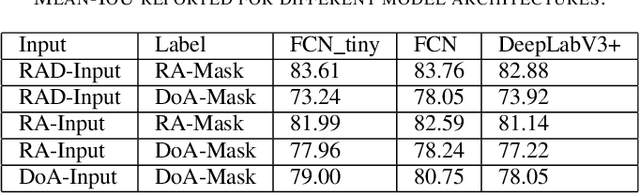
In this work, we propose the use of radar with advanced deep segmentation models to identify open space in parking scenarios. A publically available dataset of radar observations called SCORP was collected. Deep models are evaluated with various radar input representations. Our proposed approach achieves low memory usage and real-time processing speeds, and is thus very well suited for embedded deployment.
How much real data do we actually need: Analyzing object detection performance using synthetic and real data
Jul 16, 2019
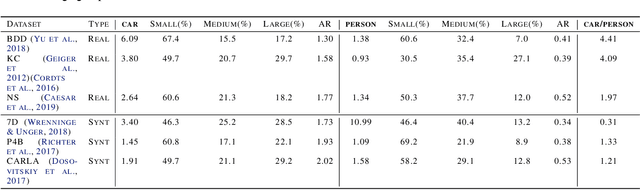

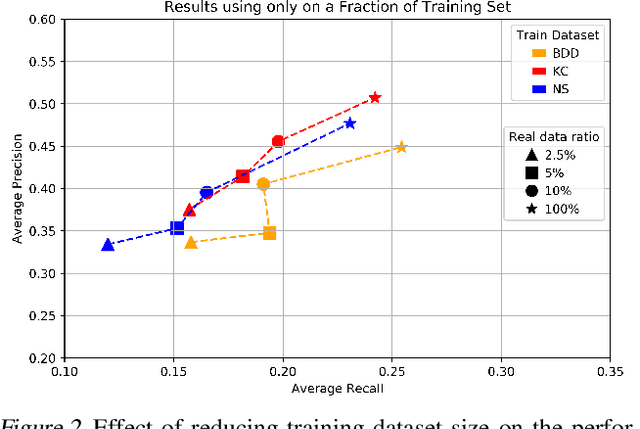
In recent years, deep learning models have resulted in a huge amount of progress in various areas, including computer vision. By nature, the supervised training of deep models requires a large amount of data to be available. This ideal case is usually not tractable as the data annotation is a tremendously exhausting and costly task to perform. An alternative is to use synthetic data. In this paper, we take a comprehensive look into the effects of replacing real data with synthetic data. We further analyze the effects of having a limited amount of real data. We use multiple synthetic and real datasets along with a simulation tool to create large amounts of cheaply annotated synthetic data. We analyze the domain similarity of each of these datasets. We provide insights about designing a methodological procedure for training deep networks using these datasets.