 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Models for Natural Language Reasoning: The Case of Syllogistic Logic
Oct 10, 2025



Despite the remarkable progress in neural models, their ability to generalize, a cornerstone for applications like logical reasoning, remains a critical challenge. We delineate two fundamental aspects of this ability: compositionality, the capacity to abstract atomic logical rules underlying complex inferences, and recursiveness, the aptitude to build intricate representations through iterative application of inference rules. In the literature, these two aspects are often confounded together under the umbrella term of generalization. To sharpen this distinction, we investigated the logical generalization capabilities of pre-trained large language models (LLMs) using the syllogistic fragment as a benchmark for natural language reasoning. Though simple, this fragment provides a foundational yet expressive subset of formal logic that supports controlled evaluation of essential reasoning abilities. Our findings reveal a significant disparity: while LLMs demonstrate reasonable proficiency in recursiveness, they struggle with compositionality. To overcome these limitations and establish a reliable logical prover, we propose a hybrid architecture integrating symbolic reasoning with neural computation. This synergistic interaction enables robust and efficient inference, neural components accelerate processing, while symbolic reasoning ensures completeness. Our experiments show that high efficiency is preserved even with relatively small neural components. As part of our proposed methodology, this analysis gives a rationale and highlights the potential of hybrid models to effectively address key generalization barriers in neural reasoning systems.
A MIND for Reasoning: Meta-learning for In-context Deduction
May 20, 2025



Large language models (LLMs) are increasingly evaluated on formal tasks, where strong reasoning abilities define the state of the art. However, their ability to generalize to out-of-distribution problems remains limited. In this paper, we investigate how LLMs can achieve a systematic understanding of deductive rules. Our focus is on the task of identifying the appropriate subset of premises within a knowledge base needed to derive a given hypothesis. To tackle this challenge, we propose Meta-learning for In-context Deduction (MIND), a novel few-shot meta-learning fine-tuning approach. The goal of MIND is to enable models to generalize more effectively to unseen knowledge bases and to systematically apply inference rules. Our results show that MIND significantly improves generalization in small LMs ranging from 1.5B to 7B parameters. The benefits are especially pronounced in smaller models and low-data settings. Remarkably, small models fine-tuned with MIND outperform state-of-the-art LLMs, such as GPT-4o and o3-mini, on this task.
Black Big Boxes: Do Language Models Hide a Theory of Adjective Order?
Jul 02, 2024



In English and other languages, multiple adjectives in a complex noun phrase show intricate ordering patterns that have been a target of much linguistic theory. These patterns offer an opportunity to assess the ability of language models (LMs) to learn subtle rules of language involving factors that cross the traditional divisions of syntax, semantics, and pragmatics. We review existing hypotheses designed to explain Adjective Order Preferences (AOPs) in humans and develop a setup to study AOPs in LMs: we present a reusable corpus of adjective pairs and define AOP measures for LMs. With these tools, we study a series of LMs across intermediate checkpoints during training. We find that all models' predictions are much closer to human AOPs than predictions generated by factors identified in theoretical linguistics. At the same time, we demonstrate that the observed AOPs in LMs are strongly correlated with the frequency of the adjective pairs in the training data and report limited generalization to unseen combinations. This highlights the difficulty in establishing the link between LM performance and linguistic theory. We therefore conclude with a road map for future studies our results set the stage for, and a discussion of key questions about the nature of knowledge in LMs and their ability to generalize beyond the training sets.
Language Models Use Monotonicity to Assess NPI Licensing
May 28, 2021
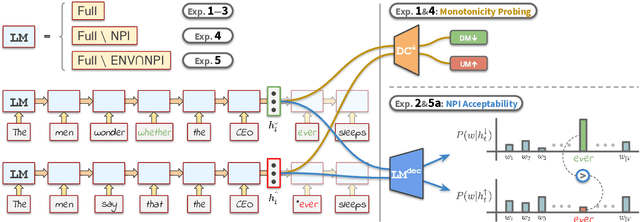


We investigate the semantic knowledge of language models (LMs), focusing on (1) whether these LMs create categories of linguistic environments based on their semantic monotonicity properties, and (2) whether these categories play a similar role in LMs as in human language understanding, using negative polarity item licensing as a case study. We introduce a series of experiments consisting of probing with diagnostic classifiers (DCs), linguistic acceptability tasks, as well as a novel DC ranking method that tightly connects the probing results to the inner workings of the LM. By applying our experimental pipeline to LMs trained on various filtered corpora, we are able to gain stronger insights into the semantic generalizations that are acquired by these models.
Some of Them Can be Guessed! Exploring the Effect of Linguistic Context in Predicting Quantifiers
Jun 01, 2018
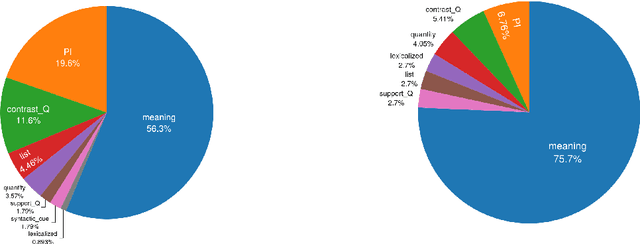
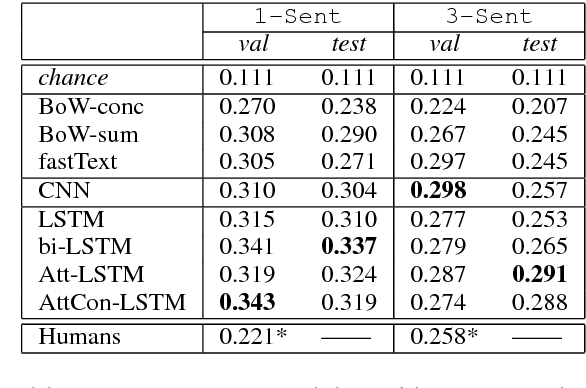
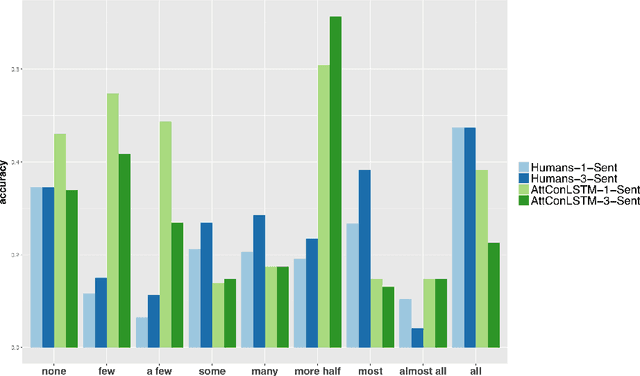
We study the role of linguistic context in predicting quantifiers (`few', `all'). We collect crowdsourced data from human participants and test various models in a local (single-sentence) and a global context (multi-sentence) condition. Models significantly out-perform humans in the former setting and are only slightly better in the latter. While human performance improves with more linguistic context (especially on proportional quantifiers), model performance suffers. Models are very effective in exploiting lexical and morpho-syntactic patterns; humans are better at genuinely understanding the meaning of the (global) context.
Parameterized Complexity Results for a Model of Theory of Mind Based on Dynamic Epistemic Logic
Jun 24, 2016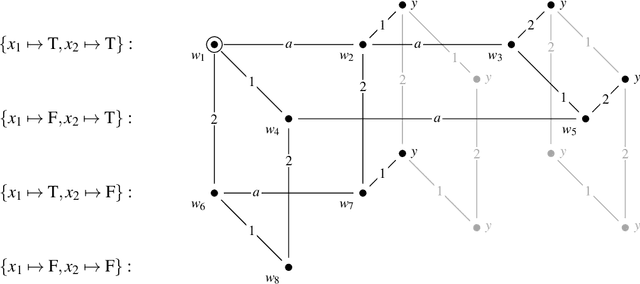

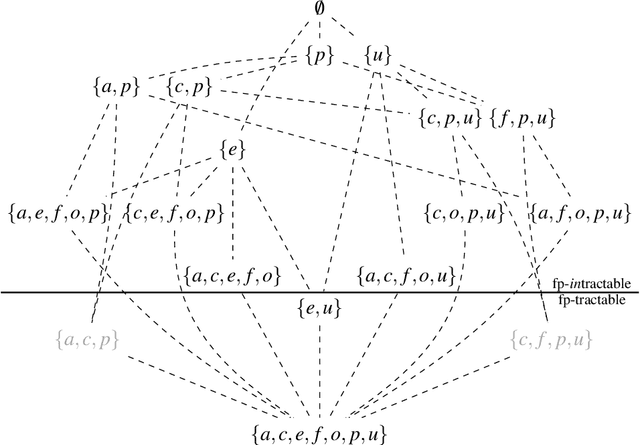
In this paper we introduce a computational-level model of theory of mind (ToM) based on dynamic epistemic logic (DEL), and we analyze its computational complexity. The model is a special case of DEL model checking. We provide a parameterized complexity analysis, considering several aspects of DEL (e.g., number of agents, size of preconditions, etc.) as parameters. We show that model checking for DEL is PSPACE-hard, also when restricted to single-pointed models and S5 relations, thereby solving an open problem in the literature. Our approach is aimed at formalizing current intractability claims in the cognitive science literature regarding computational models of ToM.
* In Proceedings TARK 2015, arXiv:1606.07295