 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Model Robustness Using Adaptive Sparse L0 Regularization
Aug 28, 2024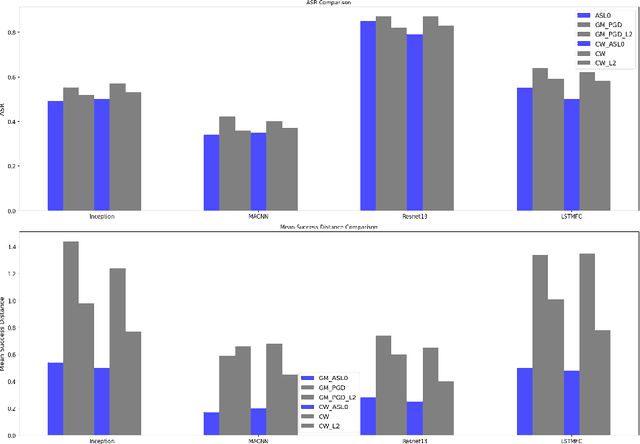
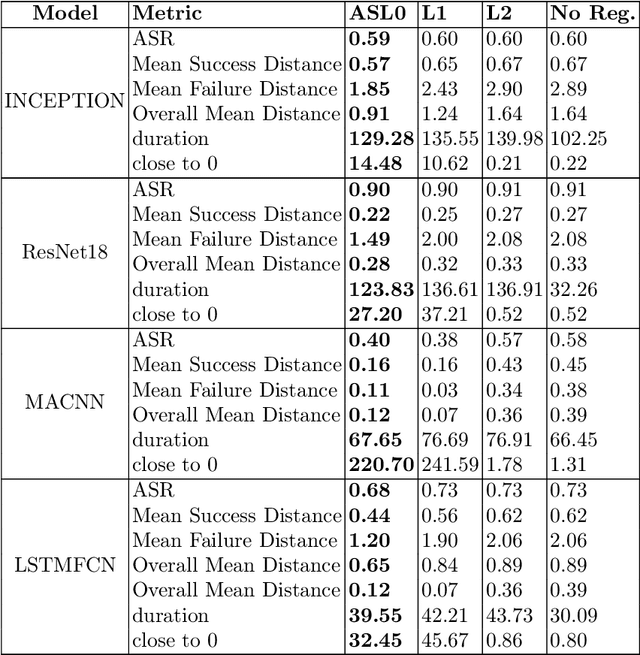
Deep Neural Networks have demonstrated remarkable success in various domains but remain susceptible to adversarial examples, which are slightly altered inputs designed to induce misclassification. While adversarial attacks typically optimize under Lp norm constraints, attacks based on the L0 norm, prioritising input sparsity, are less studied due to their complex and non convex nature. These sparse adversarial examples challenge existing defenses by altering a minimal subset of features, potentially uncovering more subtle DNN weaknesses. However, the current L0 norm attack methodologies face a trade off between accuracy and efficiency either precise but computationally intense or expedient but imprecise. This paper proposes a novel, scalable, and effective approach to generate adversarial examples based on the L0 norm, aimed at refining the robustness evaluation of DNNs against such perturbations.