 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Evidence-Based Medicine to Knowledge Graph: Retrieval-Augmented Generation for Sports Rehabilitation and a Domain Benchmark
Jan 01, 2026In medicine, large language models (LLMs) increasingly rely on retrieval-augmented generation (RAG) to ground outputs in up-to-date external evidence. However, current RAG approaches focus primarily on performance improvements while overlooking evidence-based medicine (EBM) principles. This study addresses two key gaps: (1) the lack of PICO alignment between queries and retrieved evidence, and (2) the absence of evidence hierarchy considerations during reranking. We present a generalizable strategy for adapting EBM to graph-based RAG, integrating the PICO framework into knowledge graph construction and retrieval, and proposing a Bayesian-inspired reranking algorithm to calibrate ranking scores by evidence grade without introducing predefined weights. We validated this framework in sports rehabilitation, a literature-rich domain currently lacking RAG systems and benchmarks. We released a knowledge graph (357,844 nodes and 371,226 edges) and a reusable benchmark of 1,637 QA pairs. The system achieved 0.830 nugget coverage, 0.819 answer faithfulness, 0.882 semantic similarity, and 0.788 PICOT match accuracy. In a 5-point Likert evaluation, five expert clinicians rated the system 4.66-4.84 across factual accuracy, faithfulness, relevance, safety, and PICO alignment. These findings demonstrate that the proposed EBM adaptation strategy improves retrieval and answer quality and is transferable to other clinical domains. The released resources also help address the scarcity of RAG datasets in sports rehabilitation.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
ECG-aBcDe: Overcoming Model Dependence, Encoding ECG into a Universal Language for Any LLM
Sep 16, 2025Large Language Models (LLMs) hold significant promise for electrocardiogram (ECG) analysis, yet challenges remain regarding transferability, time-scale information learning, and interpretability. Current methods suffer from model-specific ECG encoders, hindering transfer across LLMs. Furthermore, LLMs struggle to capture crucial time-scale information inherent in ECGs due to Transformer limitations. And their black-box nature limits clinical adoption. To address these limitations, we introduce ECG-aBcDe, a novel ECG encoding method that transforms ECG signals into a universal ECG language readily interpretable by any LLM. By constructing a hybrid dataset of ECG language and natural language, ECG-aBcDe enables direct fine-tuning of pre-trained LLMs without architectural modifications, achieving "construct once, use anywhere" capability. Moreover, the bidirectional convertibility between ECG and ECG language of ECG-aBcDe allows for extracting attention heatmaps from ECG signals, significantly enhancing interpretability. Finally, ECG-aBcDe explicitly represents time-scale information, mitigating Transformer limitations. This work presents a new paradigm for integrating ECG analysis with LLMs. Compared with existing methods, our method achieves competitive performance on ROUGE-L and METEOR. Notably, it delivers significant improvements in the BLEU-4, with improvements of 2.8 times and 3.9 times in in-dataset and cross-dataset evaluations, respectively, reaching scores of 42.58 and 30.76. These results provide strong evidence for the feasibility of the new paradigm.
AdsQA: Towards Advertisement Video Understanding
Sep 10, 2025Large language models (LLMs) have taken a great step towards AGI. Meanwhile, an increasing number of domain-specific problems such as math and programming boost these general-purpose models to continuously evolve via learning deeper expertise. Now is thus the time further to extend the diversity of specialized applications for knowledgeable LLMs, though collecting high quality data with unexpected and informative tasks is challenging. In this paper, we propose to use advertisement (ad) videos as a challenging test-bed to probe the ability of LLMs in perceiving beyond the objective physical content of common visual domain. Our motivation is to take full advantage of the clue-rich and information-dense ad videos' traits, e.g., marketing logic, persuasive strategies, and audience engagement. Our contribution is three-fold: (1) To our knowledge, this is the first attempt to use ad videos with well-designed tasks to evaluate LLMs. We contribute AdsQA, a challenging ad Video QA benchmark derived from 1,544 ad videos with 10,962 clips, totaling 22.7 hours, providing 5 challenging tasks. (2) We propose ReAd-R, a Deepseek-R1 styled RL model that reflects on questions, and generates answers via reward-driven optimization. (3) We benchmark 14 top-tier LLMs on AdsQA, and our \texttt{ReAd-R}~achieves the state-of-the-art outperforming strong competitors equipped with long-chain reasoning capabilities by a clear margin.
ReviewRL: Towards Automated Scientific Review with RL
Aug 14, 2025Peer review is essential for scientific progress but faces growing challenges due to increasing submission volumes and reviewer fatigue. Existing automated review approaches struggle with factual accuracy, rating consistency, and analytical depth, often generating superficial or generic feedback lacking the insights characteristic of high-quality human reviews. We introduce ReviewRL, a reinforcement learning framework for generating comprehensive and factually grounded scientific paper reviews. Our approach combines: (1) an ArXiv-MCP retrieval-augmented context generation pipeline that incorporates relevant scientific literature, (2) supervised fine-tuning that establishes foundational reviewing capabilities, and (3) a reinforcement learning procedure with a composite reward function that jointly enhances review quality and rating accuracy. Experiments on ICLR 2025 papers demonstrate that ReviewRL significantly outperforms existing methods across both rule-based metrics and model-based quality assessments. ReviewRL establishes a foundational framework for RL-driven automatic critique generation in scientific discovery, demonstrating promising potential for future development in this domain. The implementation of ReviewRL will be released at GitHub.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Quantifying Preferences of Vision-Language Models via Value Decomposition in Social Media Contexts
Nov 18, 2024The rapid advancement of Vision-Language Models (VLMs) has expanded multimodal applications, yet evaluations often focus on basic tasks like object recognition, overlooking abstract aspects such as personalities and values. To address this gap, we introduce Value-Spectrum, a visual question-answering benchmark aimed at assessing VLMs based on Schwartz's value dimensions, which capture core values guiding people's beliefs and actions across cultures. We constructed a vectorized database of over 50,000 short videos sourced from TikTok, YouTube Shorts, and Instagram Reels, covering multiple months and a wide array of topics such as family, health, hobbies, society, and technology. We also developed a VLM agent pipeline to automate video browsing and analysis. Benchmarking representative VLMs on Value-Spectrum reveals significant differences in their responses to value-oriented content, with most models exhibiting a preference for hedonistic topics. Beyond identifying natural preferences, we explored the ability of VLM agents to adopt specific personas when explicitly prompted, revealing insights into the models' adaptability in role-playing scenarios. These findings highlight the potential of Value-Spectrum as a comprehensive evaluation set for tracking VLM advancements in value-based tasks and for developing more sophisticated role-playing AI agents.
Toward Less Hidden Cost of Code Completion with Acceptance and Ranking Models
Jun 26, 2021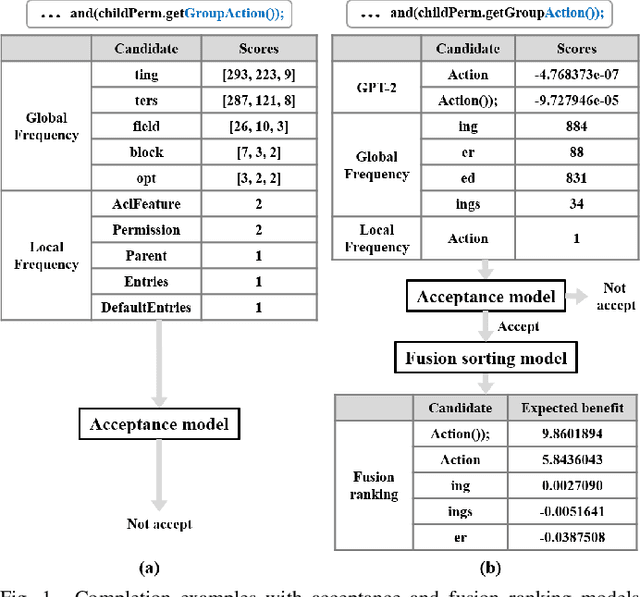
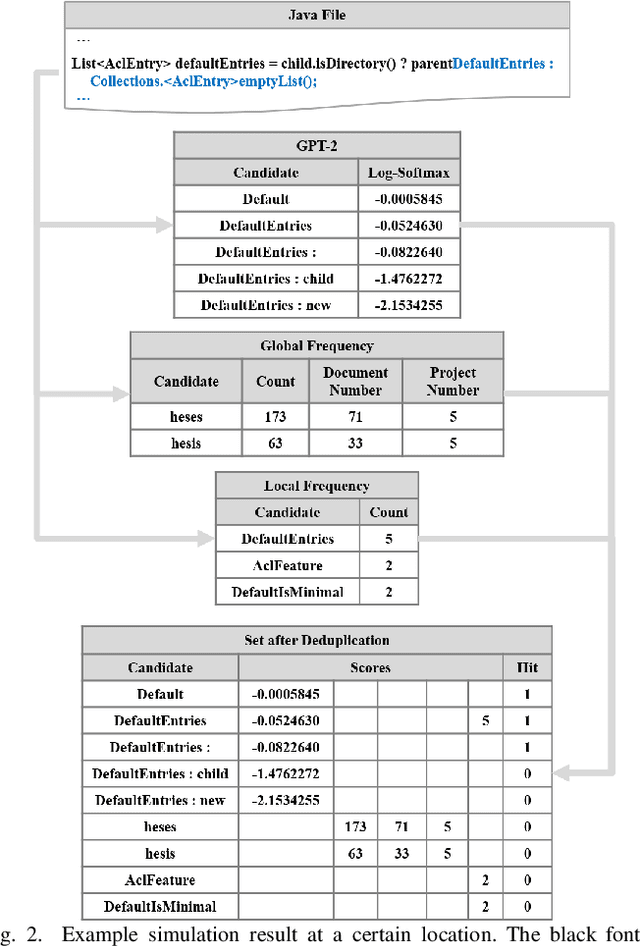

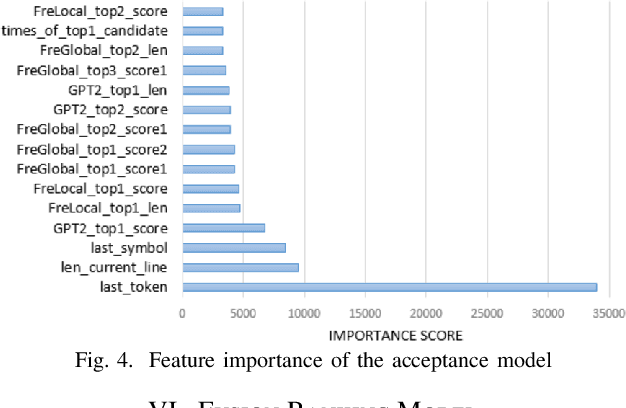
Code completion is widely used by software developers to provide coding suggestions given a partially written code snippet. Apart from the traditional code completion methods, which only support single token completion at minimal positions, recent studies show the ability to provide longer code completion at more flexible positions. However, such frequently triggered and longer completion results reduce the overall precision as they generate more invalid results. Moreover, different studies are mostly incompatible with each other. Thus, it is vital to develop an ensemble framework that can combine results from multiple models to draw merits and offset defects of each model. This paper conducts a coding simulation to collect data from code context and different code completion models and then apply the data in two tasks. First, we introduce an acceptance model which can dynamically control whether to display completion results to the developer. It uses simulation features to predict whether correct results exist in the output of these models. Our best model reduces the percentage of false-positive completion from 55.09% to 17.44%. Second, we design a fusion ranking scheme that can automatically identify the priority of the completion results and reorder the candidates from multiple code completion models. This scheme is flexible in dealing with various models, regardless of the type or the length of their completion results. We integrate this ranking scheme with two frequency models and a GPT-2 styled language model, along with the acceptance model to yield 27.80% and 37.64% increase in TOP1 and TOP5 accuracy, respectively. In addition, we propose a new code completion evaluation metric, Benefit-Cost Ratio(BCR), taking into account the benefit of keystrokes saving and hidden cost of completion list browsing, which is closer to real coder experience scenario.