 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Less Hidden Cost of Code Completion with Acceptance and Ranking Models
Jun 26, 2021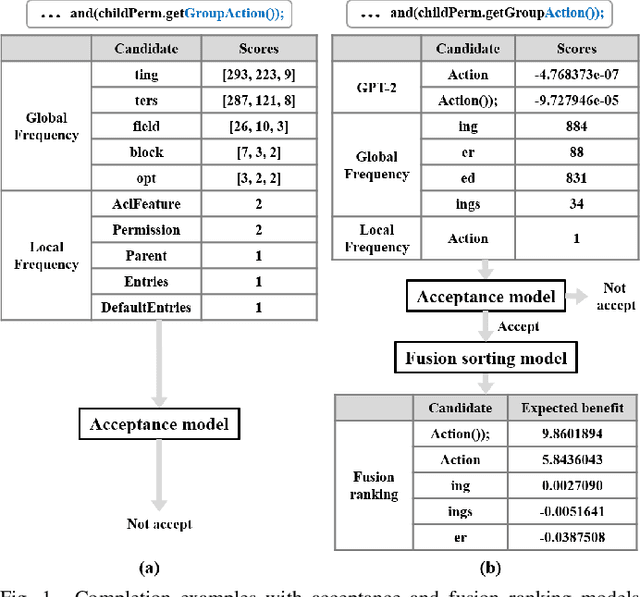
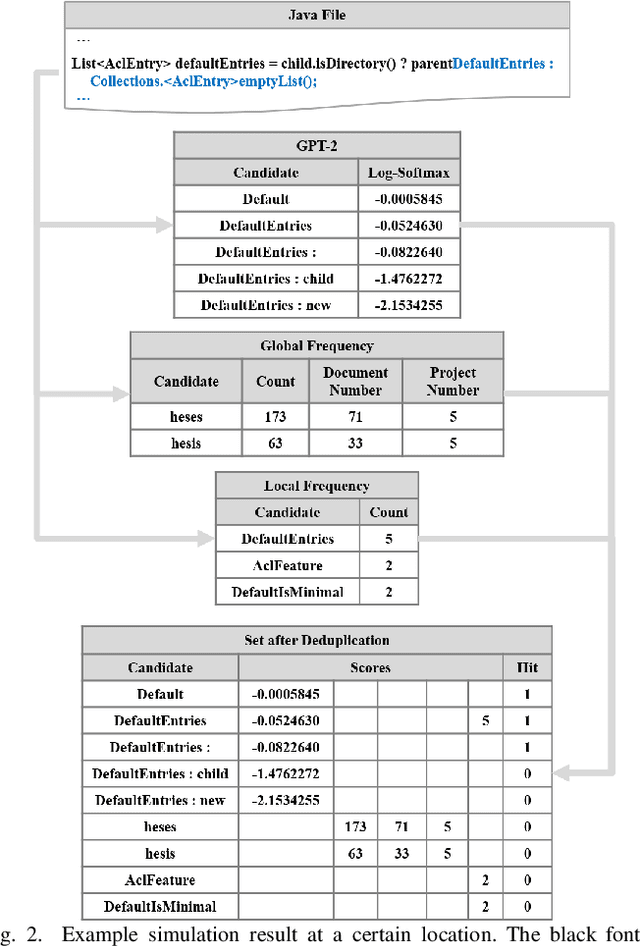

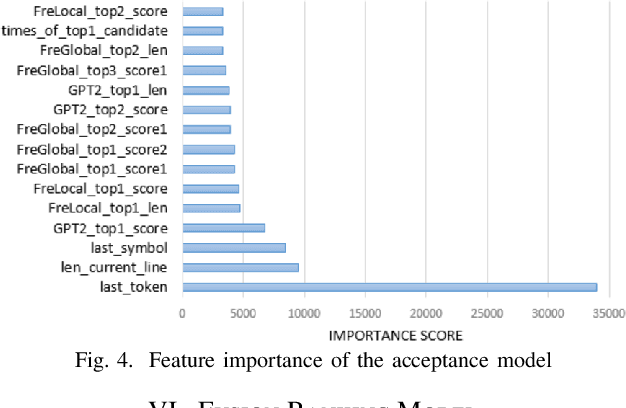
Code completion is widely used by software developers to provide coding suggestions given a partially written code snippet. Apart from the traditional code completion methods, which only support single token completion at minimal positions, recent studies show the ability to provide longer code completion at more flexible positions. However, such frequently triggered and longer completion results reduce the overall precision as they generate more invalid results. Moreover, different studies are mostly incompatible with each other. Thus, it is vital to develop an ensemble framework that can combine results from multiple models to draw merits and offset defects of each model. This paper conducts a coding simulation to collect data from code context and different code completion models and then apply the data in two tasks. First, we introduce an acceptance model which can dynamically control whether to display completion results to the developer. It uses simulation features to predict whether correct results exist in the output of these models. Our best model reduces the percentage of false-positive completion from 55.09% to 17.44%. Second, we design a fusion ranking scheme that can automatically identify the priority of the completion results and reorder the candidates from multiple code completion models. This scheme is flexible in dealing with various models, regardless of the type or the length of their completion results. We integrate this ranking scheme with two frequency models and a GPT-2 styled language model, along with the acceptance model to yield 27.80% and 37.64% increase in TOP1 and TOP5 accuracy, respectively. In addition, we propose a new code completion evaluation metric, Benefit-Cost Ratio(BCR), taking into account the benefit of keystrokes saving and hidden cost of completion list browsing, which is closer to real coder experience scenario.