 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Fourier Neural Operators
Nov 30, 2021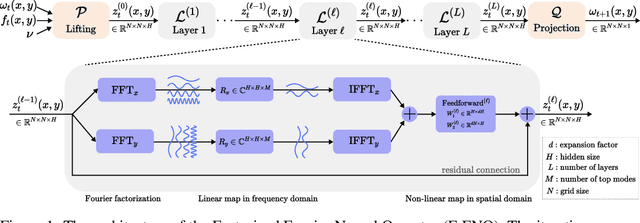
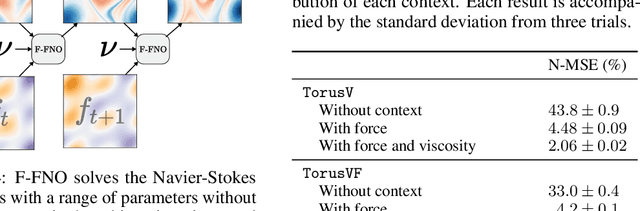
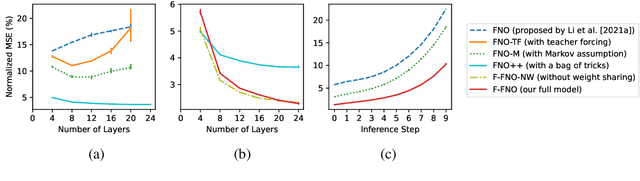

The Fourier Neural Operator (FNO) is a learning-based method for efficiently simulating partial differential equations. We propose the Factorized Fourier Neural Operator (F-FNO) that allows much better generalization with deeper networks. With a careful combination of the Fourier factorization, a shared kernel integral operator across all layers, the Markov property, and residual connections, F-FNOs achieve a six-fold reduction in error on the most turbulent setting of the Navier-Stokes benchmark dataset. We show that our model maintains an error rate of 2% while still running an order of magnitude faster than a numerical solver, even when the problem setting is extended to include additional contexts such as viscosity and time-varying forces. This enables the same pretrained neural network to model vastly different conditions.
Radflow: A Recurrent, Aggregated, and Decomposable Model for Networks of Time Series
Feb 15, 2021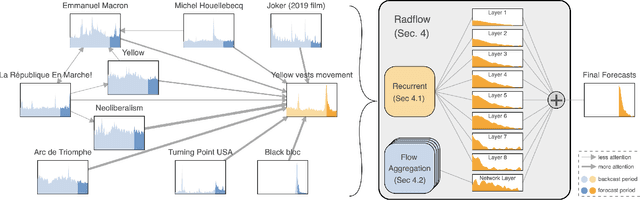
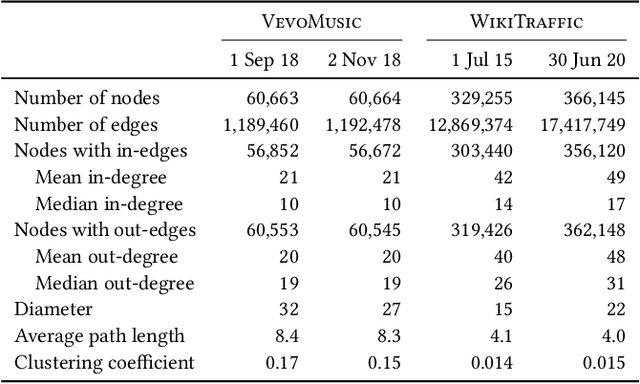
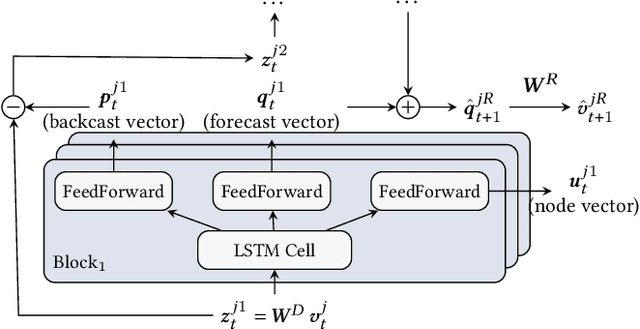
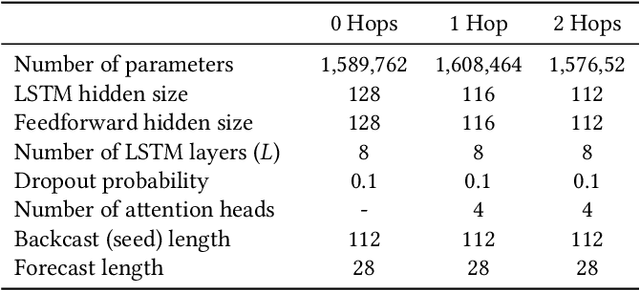
We propose a new model for networks of time series that influence each other. Graph structures among time series are found in diverse domains, such as web traffic influenced by hyperlinks, product sales influenced by recommendation, or urban transport volume influenced by road networks and weather. There has been recent progress in graph modeling and in time series forecasting, respectively, but an expressive and scalable approach for a network of series does not yet exist. We introduce Radflow, a novel model that embodies three key ideas: a recurrent neural network to obtain node embeddings that depend on time, the aggregation of the flow of influence from neighboring nodes with multi-head attention, and the multi-layer decomposition of time series. Radflow naturally takes into account dynamic networks where nodes and edges change over time, and it can be used for prediction and data imputation tasks. On real-world datasets ranging from a few hundred to a few hundred thousand nodes, we observe that Radflow variants are the best performing model across a wide range of settings. The recurrent component in Radflow also outperforms N-BEATS, the state-of-the-art time series model. We show that Radflow can learn different trends and seasonal patterns, that it is robust to missing nodes and edges, and that correlated temporal patterns among network neighbors reflect influence strength. We curate WikiTraffic, the largest dynamic network of time series with 366K nodes and 22M time-dependent links spanning five years. This dataset provides an open benchmark for developing models in this area, with applications that include optimizing resources for the web. More broadly, Radflow has the potential to improve forecasts in correlated time series networks such as the stock market, and impute missing measurements in geographically dispersed networks of natural phenomena.
* Published in The Web Conference 2021. Code is available at https://github.com/alasdairtran/radflow
AttentionFlow: Visualising Influence in Networks of Time Series
Feb 03, 2021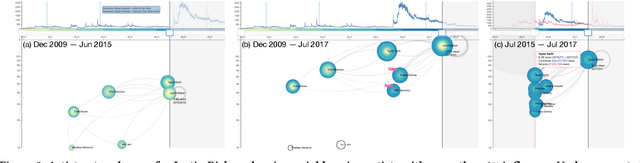
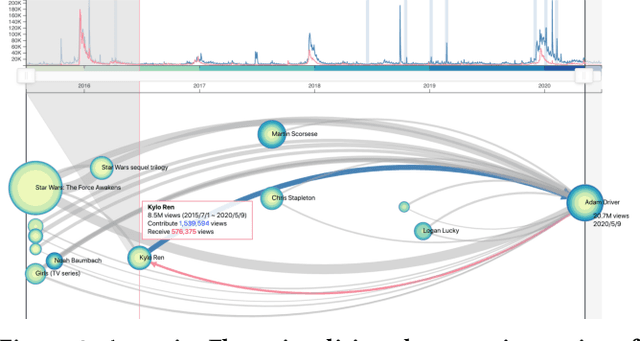
The collective attention on online items such as web pages, search terms, and videos reflects trends that are of social, cultural, and economic interest. Moreover, attention trends of different items exhibit mutual influence via mechanisms such as hyperlinks or recommendations. Many visualisation tools exist for time series, network evolution, or network influence; however, few systems connect all three. In this work, we present AttentionFlow, a new system to visualise networks of time series and the dynamic influence they have on one another. Centred around an ego node, our system simultaneously presents the time series on each node using two visual encodings: a tree ring for an overview and a line chart for details. AttentionFlow supports interactions such as overlaying time series of influence and filtering neighbours by time or flux. We demonstrate AttentionFlow using two real-world datasets, VevoMusic and WikiTraffic. We show that attention spikes in songs can be explained by external events such as major awards, or changes in the network such as the release of a new song. Separate case studies also demonstrate how an artist's influence changes over their career, and that correlated Wikipedia traffic is driven by cultural interests. More broadly, AttentionFlow can be generalised to visualise networks of time series on physical infrastructures such as road networks, or natural phenomena such as weather and geological measurements.
* Published in WSDM 2021. The demo is available at https://attentionflow.ml and code is available at https://github.com/alasdairtran/attentionflow
Universal Approximation with Neural Intensity Point Processes
Jul 28, 2020


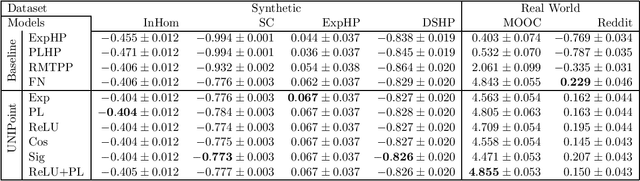
We propose a class of neural network models that universally approximate any point process intensity function. Our model can be easily applied to a wide variety of applications where the distribution of event times is of interest, such as, earthquake aftershocks, social media events, and financial transactions. Point processes have long been used to model these events, but more recently, neural network point process models have been developed to provide further flexibility. However, the theoretical foundations of these neural point processes are not well understood. We propose a neural network point process model which uses the summation of basis functions and the function composition of a transfer function to define point process intensity functions. In contrast to prior work, we prove that our model has universal approximation properties in the limit of infinite basis functions. We demonstrate how to use positive monotonic Lipschitz continuous transfer functions to shift universal approximation from the class of real valued continuous functions to the class of point process intensity functions. To this end, the Stone-Weierstrass Theorem is used to provide sufficient conditions for the sum of basis functions to achieve point process universal approximation. We further extend the notion of universal approximation mentioned in prior work for neural point processes to account for the approximation of sequences, instead of just single events. Using these insights, we design and implement a novel neural point process model that achieves strong empirical results on synthetic and real world datasets; outperforming state-of-the-art neural point process on all but one real world dataset.
Transform and Tell: Entity-Aware News Image Captioning
Apr 17, 2020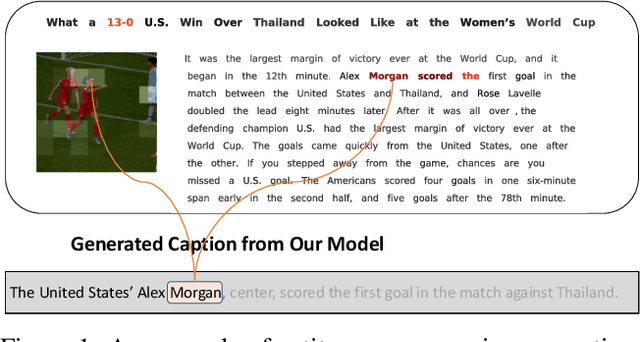
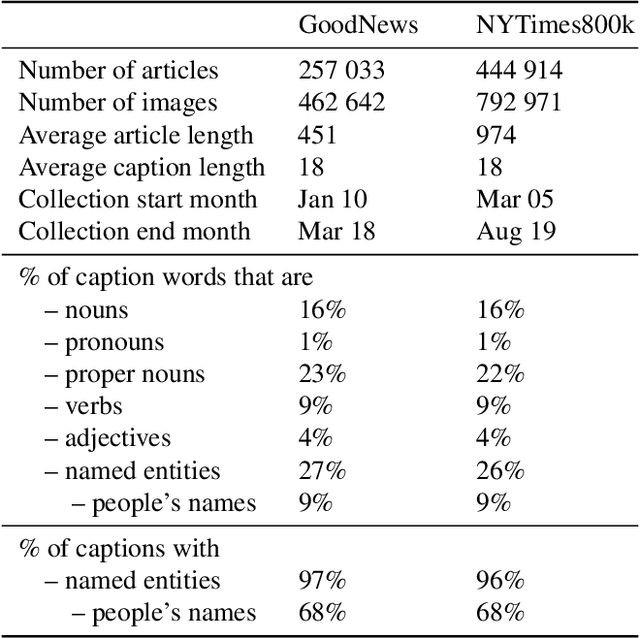
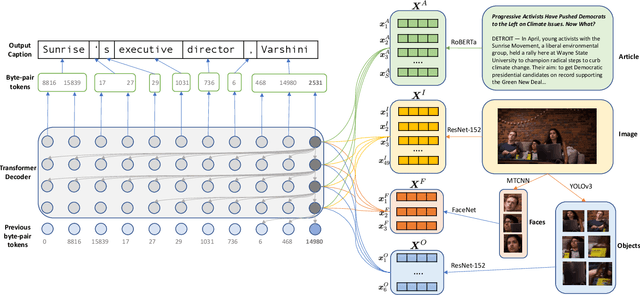
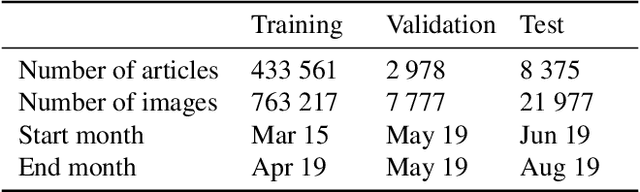
We propose an end-to-end model which generates captions for images embedded in news articles. News images present two key challenges: they rely on real-world knowledge, especially about named entities; and they typically have linguistically rich captions that include uncommon words. We address the first challenge by associating words in the caption with faces and objects in the image, via a multi-modal, multi-head attention mechanism. We tackle the second challenge with a state-of-the-art transformer language model that uses byte-pair-encoding to generate captions as a sequence of word parts. On the GoodNews dataset, our model outperforms the previous state of the art by a factor of four in CIDEr score (13 to 54). This performance gain comes from a unique combination of language models, word representation, image embeddings, face embeddings, object embeddings, and improvements in neural network design. We also introduce the NYTimes800k dataset which is 70% larger than GoodNews, has higher article quality, and includes the locations of images within articles as an additional contextual cue.
Comparative Document Summarisation via Classification
Dec 06, 2018


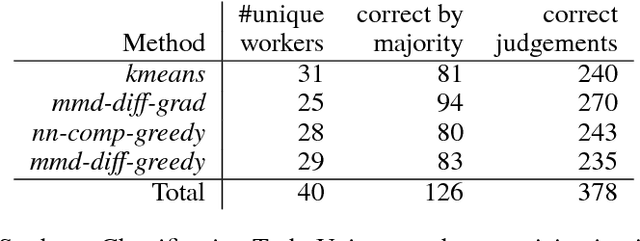
This paper considers extractive summarisation in a comparative setting: given two or more document groups (e.g., separated by publication time), the goal is to select a small number of documents that are representative of each group, and also maximally distinguishable from other groups. We formulate a set of new objective functions for this problem that connect recent literature on document summarisation, interpretable machine learning, and data subset selection. In particular, by casting the problem as a binary classification amongst different groups, we derive objectives based on the notion of maximum mean discrepancy, as well as a simple yet effective gradient-based optimisation strategy. Our new formulation allows scalable evaluations of comparative summarisation as a classification task, both automatically and via crowd-sourcing. To this end, we evaluate comparative summarisation methods on a newly curated collection of controversial news topics over 13 months. We observe that gradient-based optimisation outperforms discrete and baseline approaches in 15 out of 24 different automatic evaluation settings. In crowd-sourced evaluations, summaries from gradient optimisation elicit 7% more accurate classification from human workers than discrete optimisation. Our result contrasts with recent literature on submodular data subset selection that favours discrete optimisation. We posit that our formulation of comparative summarisation will prove useful in a diverse range of use cases such as comparing content sources, authors, related topics, or distinct view points.
SemStyle: Learning to Generate Stylised Image Captions using Unaligned Text
May 18, 2018

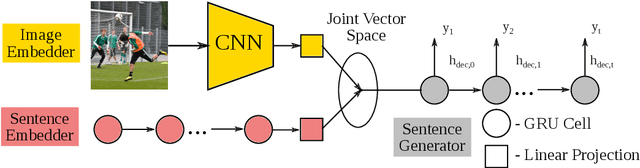
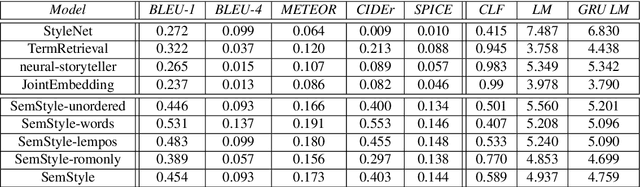
Linguistic style is an essential part of written communication, with the power to affect both clarity and attractiveness. With recent advances in vision and language, we can start to tackle the problem of generating image captions that are both visually grounded and appropriately styled. Existing approaches either require styled training captions aligned to images or generate captions with low relevance. We develop a model that learns to generate visually relevant styled captions from a large corpus of styled text without aligned images. The core idea of this model, called SemStyle, is to separate semantics and style. One key component is a novel and concise semantic term representation generated using natural language processing techniques and frame semantics. In addition, we develop a unified language model that decodes sentences with diverse word choices and syntax for different styles. Evaluations, both automatic and manual, show captions from SemStyle preserve image semantics, are descriptive, and are style shifted. More broadly, this work provides possibilities to learn richer image descriptions from the plethora of linguistic data available on the web.
Simplifying Sentences with Sequence to Sequence Models
May 15, 2018


We simplify sentences with an attentive neural network sequence to sequence model, dubbed S4. The model includes a novel word-copy mechanism and loss function to exploit linguistic similarities between the original and simplified sentences. It also jointly uses pre-trained and fine-tuned word embeddings to capture the semantics of complex sentences and to mitigate the effects of limited data. When trained and evaluated on pairs of sentences from thousands of news articles, we observe a 8.8 point improvement in BLEU score over a sequence to sequence baseline; however, learning word substitutions remains difficult. Such sequence to sequence models are promising for other text generation tasks such as style transfer.
SentiCap: Generating Image Descriptions with Sentiments
Dec 13, 2015



The recent progress on image recognition and language modeling is making automatic description of image content a reality. However, stylized, non-factual aspects of the written description are missing from the current systems. One such style is descriptions with emotions, which is commonplace in everyday communication, and influences decision-making and interpersonal relationships. We design a system to describe an image with emotions, and present a model that automatically generates captions with positive or negative sentiments. We propose a novel switching recurrent neural network with word-level regularization, which is able to produce emotional image captions using only 2000+ training sentences containing sentiments. We evaluate the captions with different automatic and crowd-sourcing metrics. Our model compares favourably in common quality metrics for image captioning. In 84.6% of cases the generated positive captions were judged as being at least as descriptive as the factual captions. Of these positive captions 88% were confirmed by the crowd-sourced workers as having the appropriate sentiment.