 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupMMD: A Sentence Importance Model for Extractive Summarization using Maximum Mean Discrepancy
Oct 06, 2020
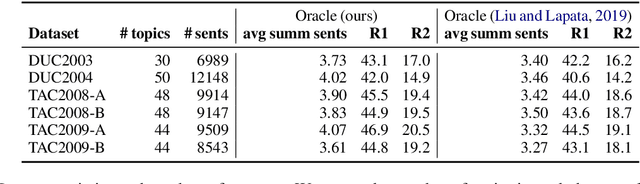
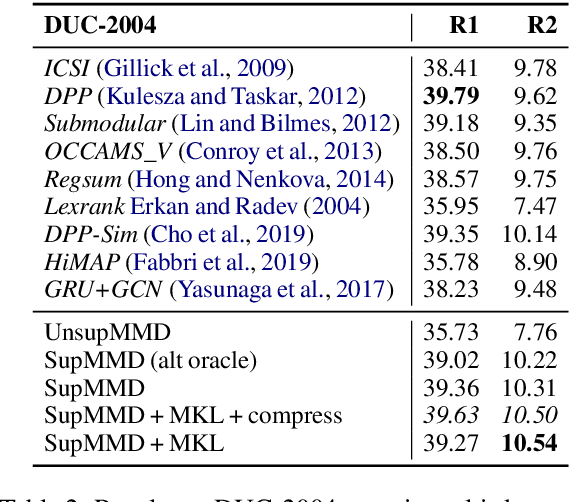

Most work on multi-document summarization has focused on generic summarization of information present in each individual document set. However, the under-explored setting of update summarization, where the goal is to identify the new information present in each set, is of equal practical interest (e.g., presenting readers with updates on an evolving news topic). In this work, we present SupMMD, a novel technique for generic and update summarization based on the maximum mean discrepancy from kernel two-sample testing. SupMMD combines both supervised learning for salience and unsupervised learning for coverage and diversity. Further, we adapt multiple kernel learning to make use of similarity across multiple information sources (e.g., text features and knowledge based concepts). We show the efficacy of SupMMD in both generic and update summarization tasks by meeting or exceeding the current state-of-the-art on the DUC-2004 and TAC-2009 datasets.
* 15 pages
Comparative Document Summarisation via Classification
Dec 06, 2018


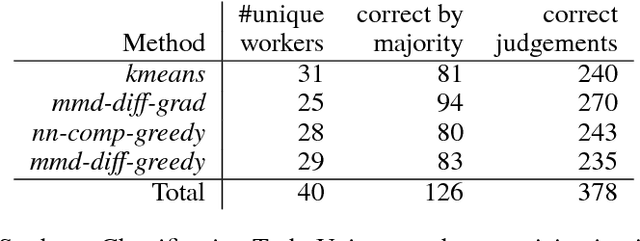
This paper considers extractive summarisation in a comparative setting: given two or more document groups (e.g., separated by publication time), the goal is to select a small number of documents that are representative of each group, and also maximally distinguishable from other groups. We formulate a set of new objective functions for this problem that connect recent literature on document summarisation, interpretable machine learning, and data subset selection. In particular, by casting the problem as a binary classification amongst different groups, we derive objectives based on the notion of maximum mean discrepancy, as well as a simple yet effective gradient-based optimisation strategy. Our new formulation allows scalable evaluations of comparative summarisation as a classification task, both automatically and via crowd-sourcing. To this end, we evaluate comparative summarisation methods on a newly curated collection of controversial news topics over 13 months. We observe that gradient-based optimisation outperforms discrete and baseline approaches in 15 out of 24 different automatic evaluation settings. In crowd-sourced evaluations, summaries from gradient optimisation elicit 7% more accurate classification from human workers than discrete optimisation. Our result contrasts with recent literature on submodular data subset selection that favours discrete optimisation. We posit that our formulation of comparative summarisation will prove useful in a diverse range of use cases such as comparing content sources, authors, related topics, or distinct view points.
Describing Natural Images Containing Novel Objects with Knowledge Guided Assitance
Oct 17, 2017
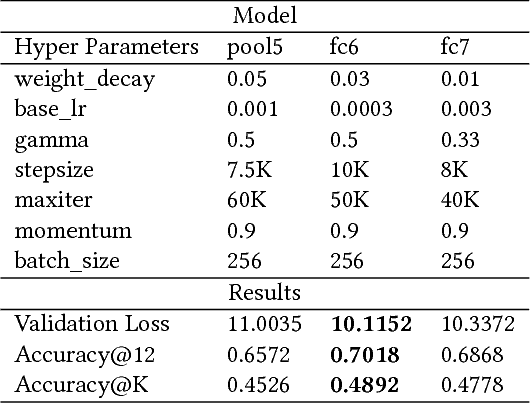
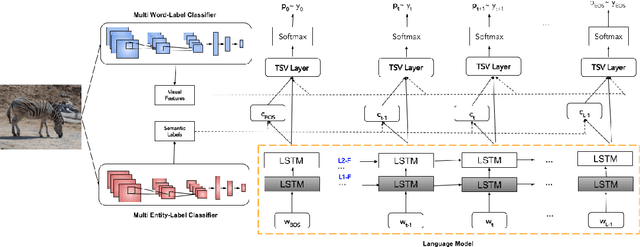
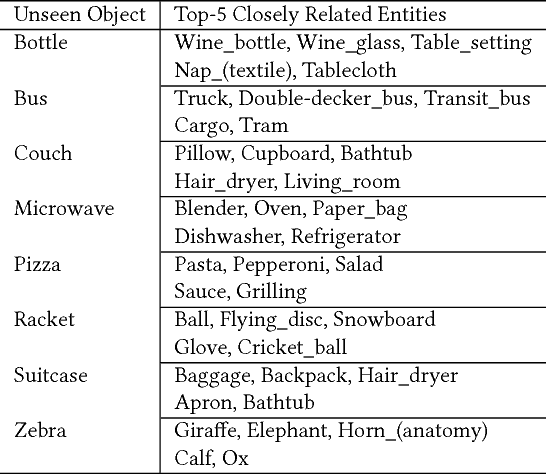
Images in the wild encapsulate rich knowledge about varied abstract concepts and cannot be sufficiently described with models built only using image-caption pairs containing selected objects. We propose to handle such a task with the guidance of a knowledge base that incorporate many abstract concepts. Our method is a two-step process where we first build a multi-entity-label image recognition model to predict abstract concepts as image labels and then leverage them in the second step as an external semantic attention and constrained inference in the caption generation model for describing images that depict unseen/novel objects. Evaluations show that our models outperform most of the prior work for out-of-domain captioning on MSCOCO and are useful for integration of knowledge and vision in general.