 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing Natural Images Containing Novel Objects with Knowledge Guided Assitance
Paper and Code
Oct 17, 2017
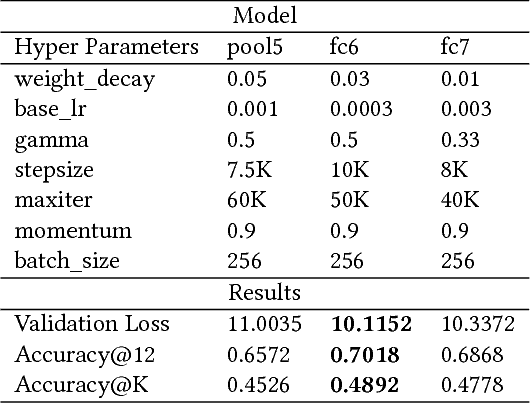
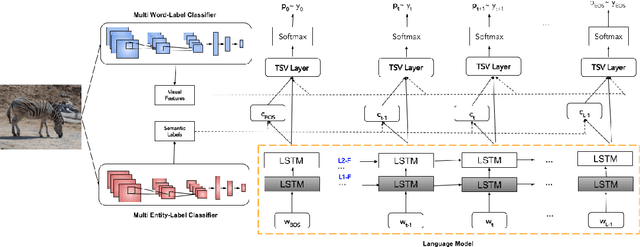
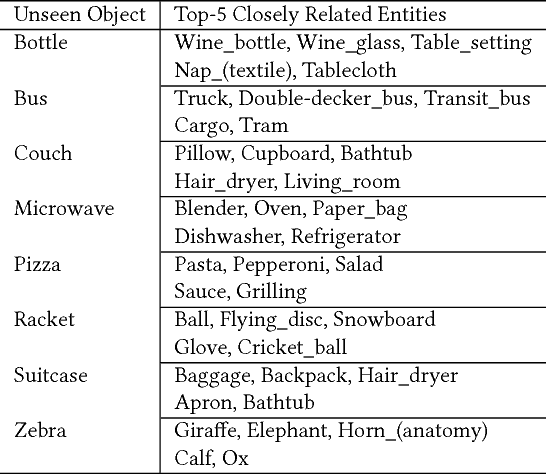
Images in the wild encapsulate rich knowledge about varied abstract concepts and cannot be sufficiently described with models built only using image-caption pairs containing selected objects. We propose to handle such a task with the guidance of a knowledge base that incorporate many abstract concepts. Our method is a two-step process where we first build a multi-entity-label image recognition model to predict abstract concepts as image labels and then leverage them in the second step as an external semantic attention and constrained inference in the caption generation model for describing images that depict unseen/novel objects. Evaluations show that our models outperform most of the prior work for out-of-domain captioning on MSCOCO and are useful for integration of knowledge and vision in general.