 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Category Correlations for Multi-label Image Recognition with Graph Networks
Sep 28, 2019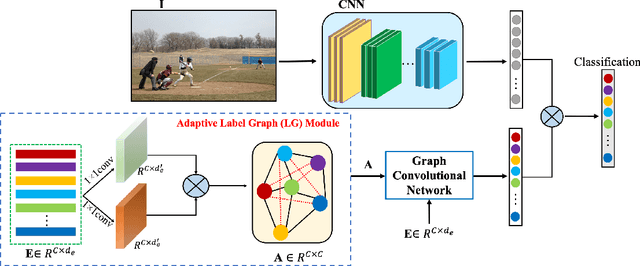

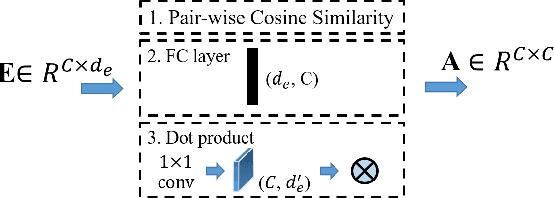
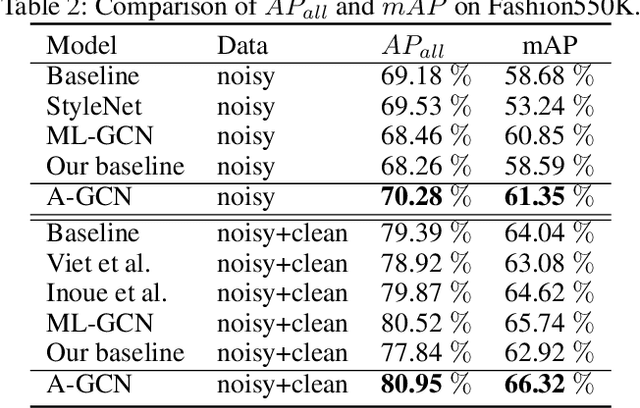
Multi-label image recognition is a task that predicts a set of object labels in an image. As the objects co-occur in the physical world, it is desirable to model label dependencies. Previous existing methods resort to either recurrent networks or pre-defined label correlation graphs for this purpose. In this paper, instead of using a pre-defined graph which is inflexible and may be sub-optimal for multi-label classification, we propose the A-GCN, which leverages the popular Graph Convolutional Networks with an Adaptive label correlation graph to model label dependencies. Specifically, we introduce a plug-and-play Label Graph (LG) module to learn label correlations with word embeddings, and then utilize traditional GCN to map this graph into label-dependent object classifiers which are further applied to image features. The basic LG module incorporates two 1x1 convolutional layers and uses the dot product to generate label graphs. In addition, we propose a sparse correlation constraint to enhance the LG module and also explore different LG architectures. We validate our method on two diverse multi-label datasets: MS-COCO and Fashion550K. Experimental results show that our A-GCN significantly improves baseline methods and achieves performance superior or comparable to the state of the art.
Multiple VLAD encoding of CNNs for image classification
Jun 30, 2017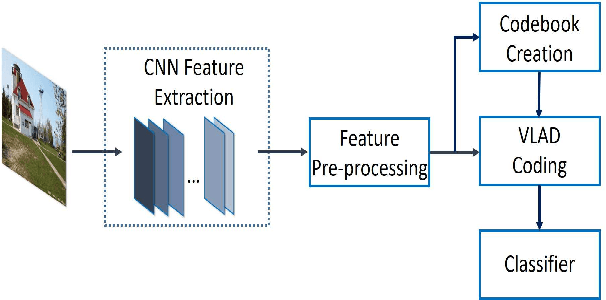
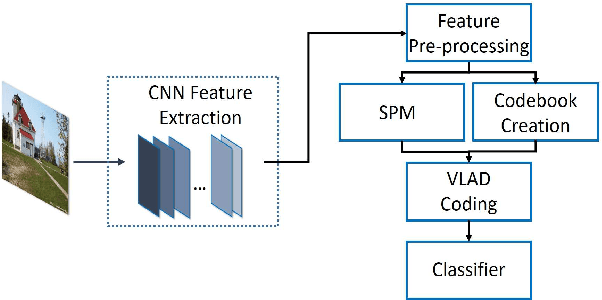


Despite the effectiveness of convolutional neural networks (CNNs) especially in image classification tasks, the effect of convolution features on learned representations is still limited. It mostly focuses on the salient object of the images, but ignores the variation information on clutter and local. In this paper, we propose a special framework, which is the multiple VLAD encoding method with the CNNs features for image classification. Furthermore, in order to improve the performance of the VLAD coding method, we explore the multiplicity of VLAD encoding with the extension of three kinds of encoding algorithms, which are the VLAD-SA method, the VLAD-LSA and the VLAD-LLC method. Finally, we equip the spatial pyramid patch (SPM) on VLAD encoding to add the spatial information of CNNs feature. In particular, the power of SPM leads our framework to yield better performance compared to the existing method.
Diversified Visual Attention Networks for Fine-Grained Object Classification
May 18, 2017
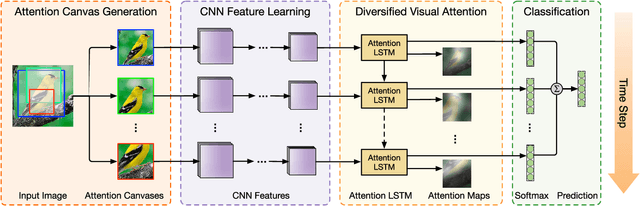
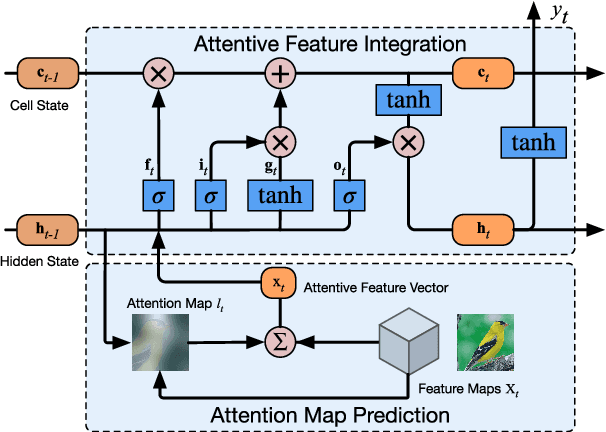

Fine-grained object classification is a challenging task due to the subtle inter-class difference and large intra-class variation. Recently, visual attention models have been applied to automatically localize the discriminative regions of an image for better capturing critical difference and demonstrated promising performance. However, without consideration of the diversity in attention process, most of existing attention models perform poorly in classifying fine-grained objects. In this paper, we propose a diversified visual attention network (DVAN) to address the problems of fine-grained object classification, which substan- tially relieves the dependency on strongly-supervised information for learning to localize discriminative regions compared with attentionless models. More importantly, DVAN explicitly pursues the diversity of attention and is able to gather discriminative information to the maximal extent. Multiple attention canvases are generated to extract convolutional features for attention. An LSTM recurrent unit is employed to learn the attentiveness and discrimination of attention canvases. The proposed DVAN has the ability to attend the object from coarse to fine granularity, and a dynamic internal representation for classification is built up by incrementally combining the information from different locations and scales of the image. Extensive experiments con- ducted on CUB-2011, Stanford Dogs and Stanford Cars datasets have demonstrated that the proposed diversified visual attention networks achieve competitive performance compared to the state- of-the-art approaches, without using any prior knowledge, user interaction or external resource in training or testing.
A Study on Unsupervised Dictionary Learning and Feature Encoding for Action Classification
Sep 02, 2013
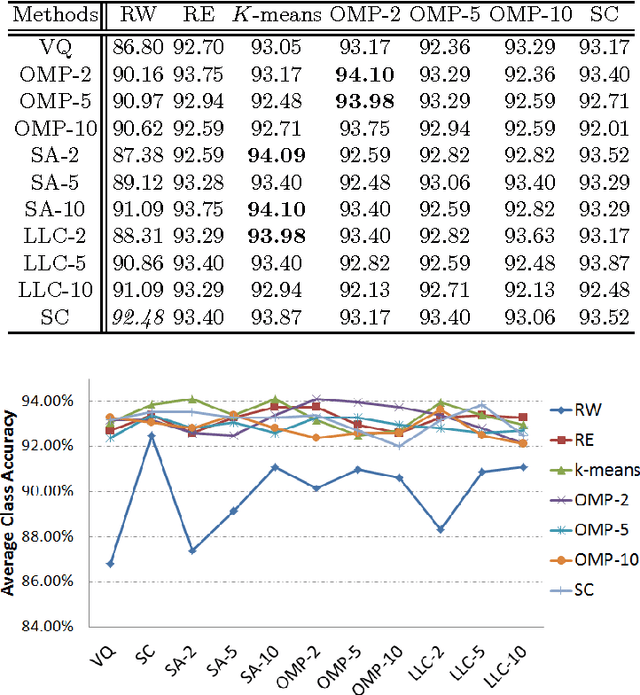

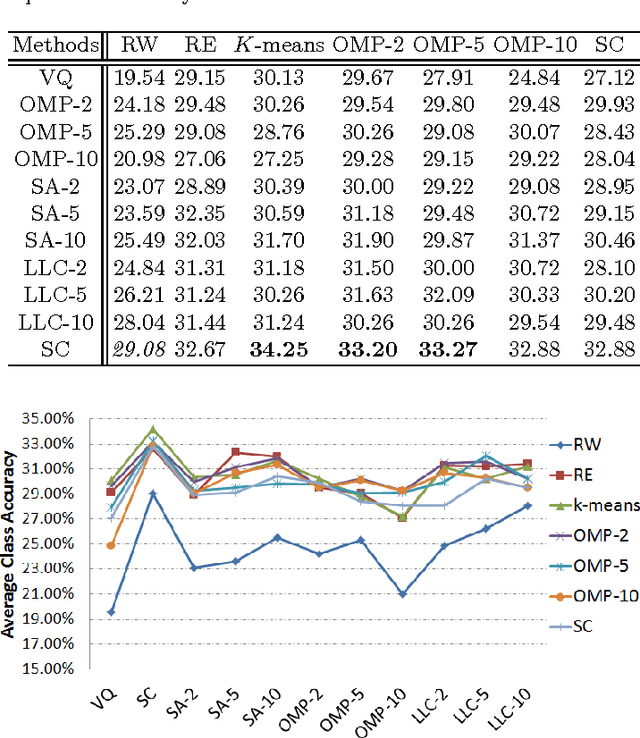
Many efforts have been devoted to develop alternative methods to traditional vector quantization in image domain such as sparse coding and soft-assignment. These approaches can be split into a dictionary learning phase and a feature encoding phase which are often closely connected. In this paper, we investigate the effects of these phases by separating them for video-based action classification. We compare several dictionary learning methods and feature encoding schemes through extensive experiments on KTH and HMDB51 datasets. Experimental results indicate that sparse coding performs consistently better than the other encoding methods in large complex dataset (i.e., HMDB51), and it is robust to different dictionaries. For small simple dataset (i.e., KTH) with less variation, however, all the encoding strategies perform competitively. In addition, we note that the strength of sophisticated encoding approaches comes not from their corresponding dictionaries but the encoding mechanisms, and we can just use randomly selected exemplars as dictionaries for video-based action classification.