 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversified Visual Attention Networks for Fine-Grained Object Classification
Paper and Code
May 18, 2017
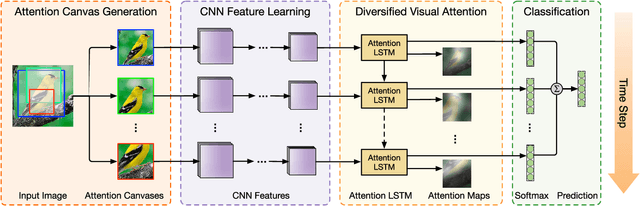
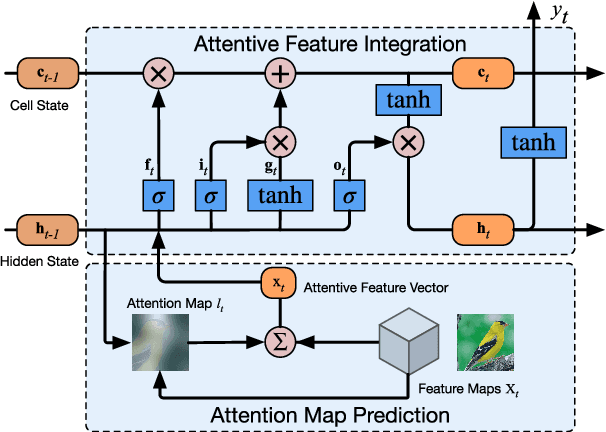

Fine-grained object classification is a challenging task due to the subtle inter-class difference and large intra-class variation. Recently, visual attention models have been applied to automatically localize the discriminative regions of an image for better capturing critical difference and demonstrated promising performance. However, without consideration of the diversity in attention process, most of existing attention models perform poorly in classifying fine-grained objects. In this paper, we propose a diversified visual attention network (DVAN) to address the problems of fine-grained object classification, which substan- tially relieves the dependency on strongly-supervised information for learning to localize discriminative regions compared with attentionless models. More importantly, DVAN explicitly pursues the diversity of attention and is able to gather discriminative information to the maximal extent. Multiple attention canvases are generated to extract convolutional features for attention. An LSTM recurrent unit is employed to learn the attentiveness and discrimination of attention canvases. The proposed DVAN has the ability to attend the object from coarse to fine granularity, and a dynamic internal representation for classification is built up by incrementally combining the information from different locations and scales of the image. Extensive experiments con- ducted on CUB-2011, Stanford Dogs and Stanford Cars datasets have demonstrated that the proposed diversified visual attention networks achieve competitive performance compared to the state- of-the-art approaches, without using any prior knowledge, user interaction or external resource in training or testing.