 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-policy Maximum Entropy Reinforcement Learning : Soft Actor-Critic with Advantage Weighted Mixture Policy(SAC-AWMP)
Paper and Code
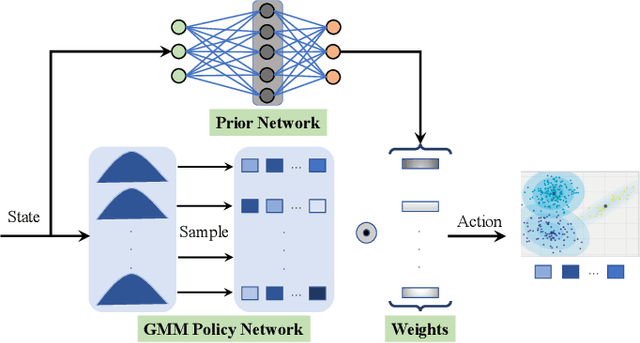
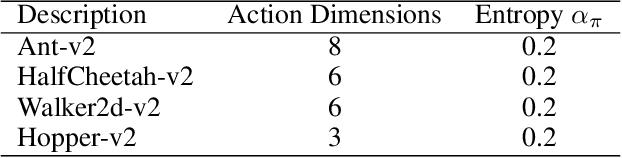

The optimal policy of a reinforcement learning problem is often discontinuous and non-smooth. I.e., for two states with similar representations, their optimal policies can be significantly different. In this case, representing the entire policy with a function approximator (FA) with shared parameters for all states maybe not desirable, as the generalization ability of parameters sharing makes representing discontinuous, non-smooth policies difficult. A common way to solve this problem, known as Mixture-of-Experts, is to represent the policy as the weighted sum of multiple components, where different components perform well on different parts of the state space. Following this idea and inspired by a recent work called advantage-weighted information maximization, we propose to learn for each state weights of these components, so that they entail the information of the state itself and also the preferred action learned so far for the state. The action preference is characterized via the advantage function. In this case, the weight of each component would only be large for certain groups of states whose representations are similar and preferred action representations are also similar. Therefore each component is easy to be represented. We call a policy parameterized in this way an Advantage Weighted Mixture Policy (AWMP) and apply this idea to improve soft-actor-critic (SAC), one of the most competitive continuous control algorithm. Experimental results demonstrate that SAC with AWMP clearly outperforms SAC in four commonly used continuous control tasks and achieve stable performance across different random seeds.