 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does the structure embedded in learning policy affect learning quadruped locomotion?
Aug 29, 2020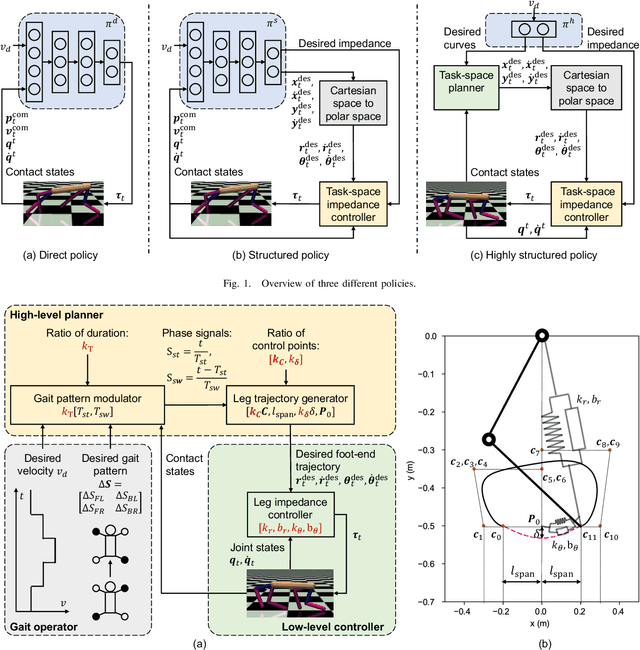
Reinforcement learning (RL) is a popular data-driven method that has demonstrated great success in robotics. Previous works usually focus on learning an end-to-end (direct) policy to directly output joint torques. While the direct policy seems convenient, the resultant performance may not meet our expectations. To improve its performance, more sophisticated reward functions or more structured policies can be utilized. This paper focuses on the latter because the structured policy is more intuitive and can inherit insights from previous model-based controllers. It is unsurprising that the structure, such as a better choice of the action space and constraints of motion trajectory, may benefit the training process and the final performance of the policy at the cost of generality, but the quantitative effect is still unclear. To analyze the effect of the structure quantitatively, this paper investigates three policies with different levels of structure in learning quadruped locomotion: a direct policy, a structured policy, and a highly structured policy. The structured policy is trained to learn a task-space impedance controller and the highly structured policy learns a controller tailored for trot running, which we adopt from previous work. To evaluate trained policies, we design a simulation experiment to track different desired velocities under force disturbances. Simulation results show that structured policy and highly structured policy require 1/3 and 3/4 fewer training steps than the direct policy to achieve a similar level of cumulative reward, and seem more robust and efficient than the direct policy. We highlight that the structure embedded in the policies significantly affects the overall performance of learning a complicated task when complex dynamics are involved, such as legged locomotion.