 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSync-DRAW: Automatic Video Generation using Deep Recurrent Attentive Architectures
Paper and Code

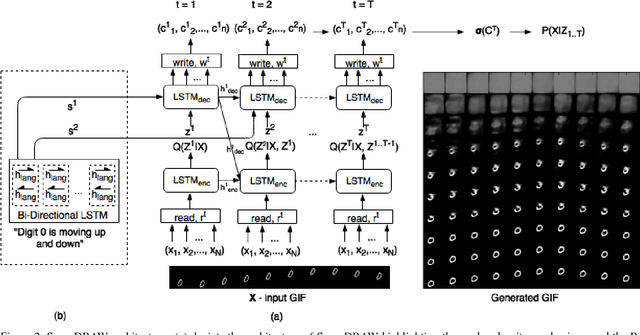


This paper introduces a novel approach for generating videos called Synchronized Deep Recurrent Attentive Writer (Sync-DRAW). Sync-DRAW can also perform text-to-video generation which, to the best of our knowledge, makes it the first approach of its kind. It combines a Variational Autoencoder~(VAE) with a Recurrent Attention Mechanism in a novel manner to create a temporally dependent sequence of frames that are gradually formed over time. The recurrent attention mechanism in Sync-DRAW attends to each individual frame of the video in sychronization, while the VAE learns a latent distribution for the entire video at the global level. Our experiments with Bouncing MNIST, KTH and UCF-101 suggest that Sync-DRAW is efficient in learning the spatial and temporal information of the videos and generates frames with high structural integrity, and can generate videos from simple captions on these datasets. (Accepted as oral paper in ACM-Multimedia 2017)