 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Adaptive Prototypical Contrastive Embedding for Generalized Zero Shot Learning
Sep 14, 2023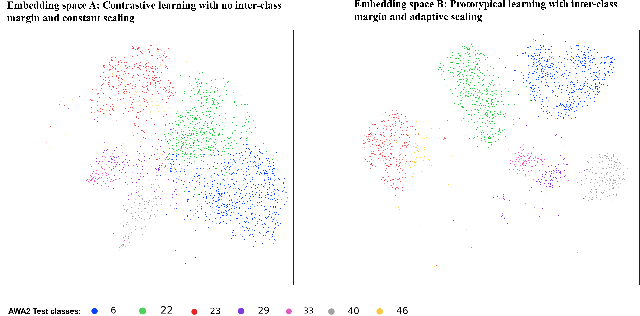
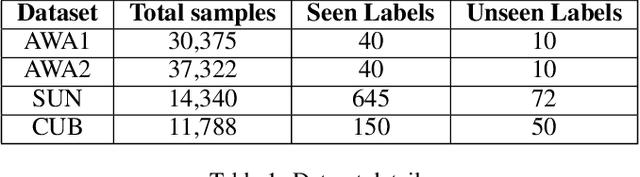
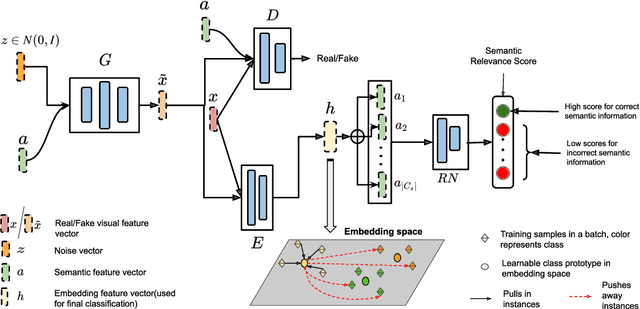
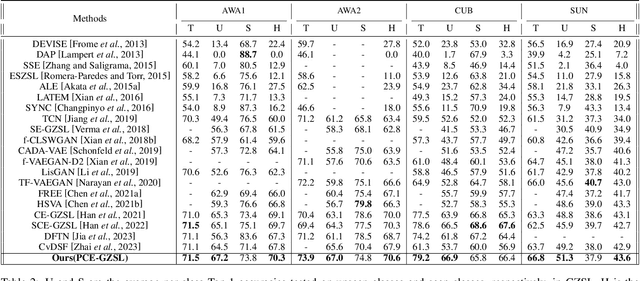
Generalized zero-shot learning(GZSL) aims to classify samples from seen and unseen labels, assuming unseen labels are not accessible during training. Recent advancements in GZSL have been expedited by incorporating contrastive-learning-based (instance-based) embedding in generative networks and leveraging the semantic relationship between data points. However, existing embedding architectures suffer from two limitations: (1) limited discriminability of synthetic features' embedding without considering fine-grained cluster structures; (2) inflexible optimization due to restricted scaling mechanisms on existing contrastive embedding networks, leading to overlapped representations in the embedding space. To enhance the quality of representations in the embedding space, as mentioned in (1), we propose a margin-based prototypical contrastive learning embedding network that reaps the benefits of prototype-data (cluster quality enhancement) and implicit data-data (fine-grained representations) interaction while providing substantial cluster supervision to the embedding network and the generator. To tackle (2), we propose an instance adaptive contrastive loss that leads to generalized representations for unseen labels with increased inter-class margin. Through comprehensive experimental evaluation, we show that our method can outperform the current state-of-the-art on three benchmark datasets. Our approach also consistently achieves the best unseen performance in the GZSL setting.
Partial Domain Adaptation Using Selective Representation Learning For Class-Weight Computation
Jan 06, 2021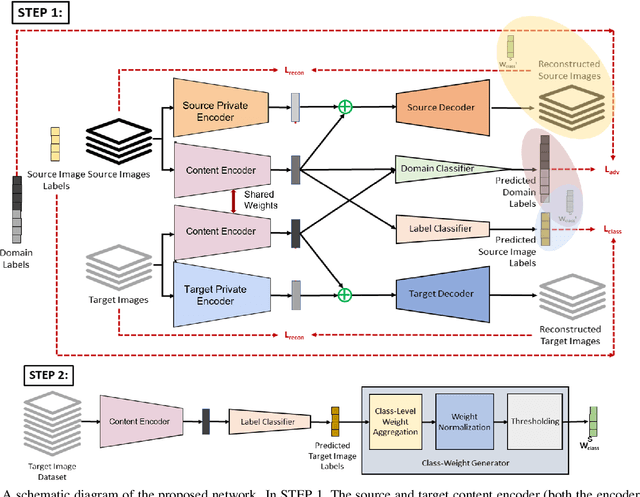
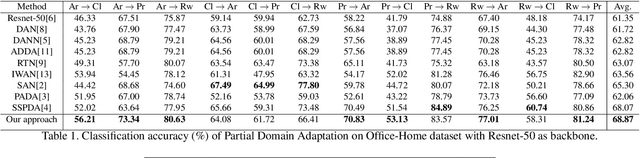
The generalization power of deep-learning models is dependent on rich-labelled data. This supervision using large-scaled annotated information is restrictive in most real-world scenarios where data collection and their annotation involve huge cost. Various domain adaptation techniques exist in literature that bridge this distribution discrepancy. However, a majority of these models require the label sets of both the domains to be identical. To tackle a more practical and challenging scenario, we formulate the problem statement from a partial domain adaptation perspective, where the source label set is a super set of the target label set. Driven by the motivation that image styles are private to each domain, in this work, we develop a method that identifies outlier classes exclusively from image content information and train a label classifier exclusively on class-content from source images. Additionally, elimination of negative transfer of samples from classes private to the source domain is achieved by transforming the soft class-level weights into two clusters, 0 (outlier source classes) and 1 (shared classes) by maximizing the between-cluster variance between them.