 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmony-Search and Otsu based System for Coronavirus Disease Detection using Lung CT Scan Images
Apr 06, 2020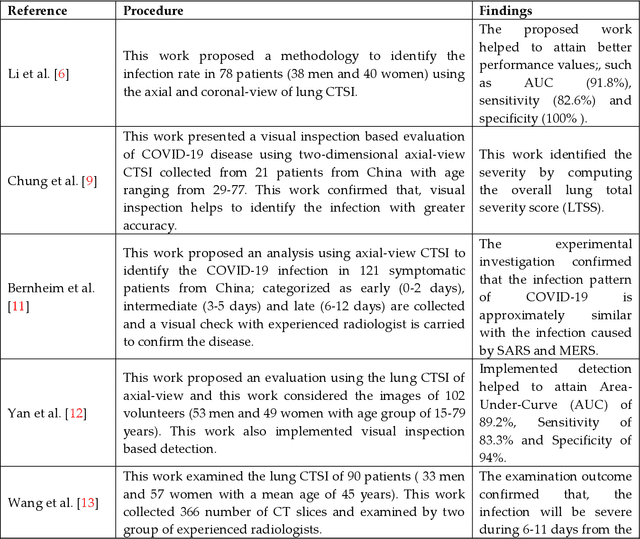
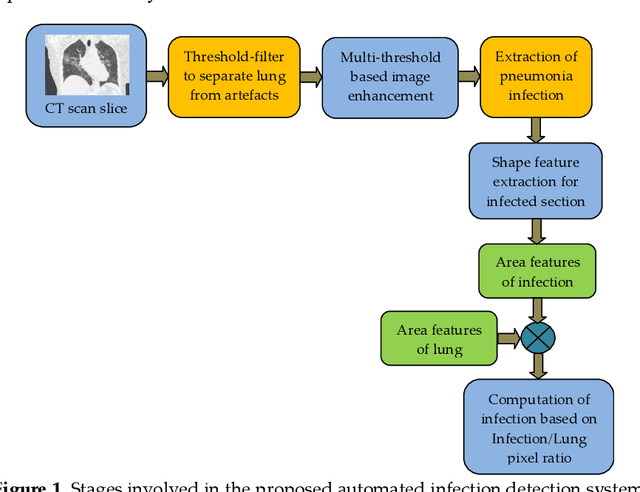
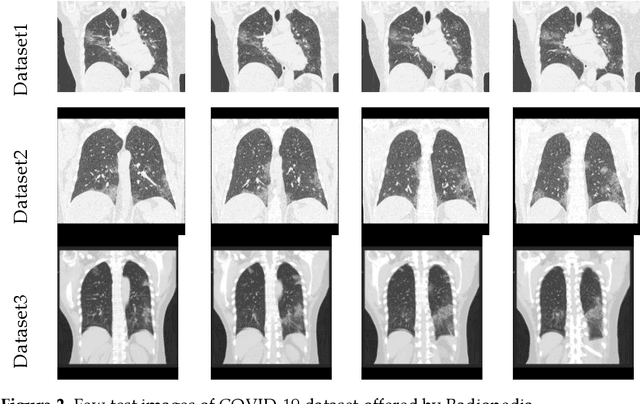
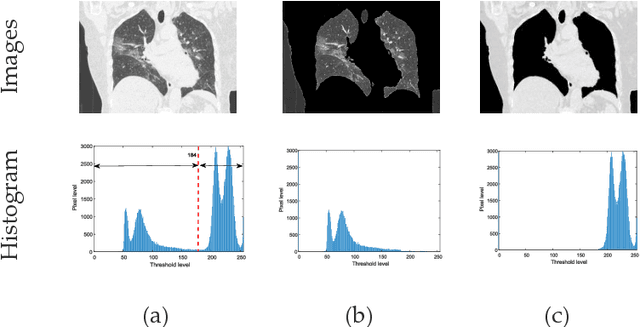
Pneumonia is one of the foremost lung diseases and untreated pneumonia will lead to serious threats for all age groups. The proposed work aims to extract and evaluate the Coronavirus disease (COVID-19) caused pneumonia infection in lung using CT scans. We propose an image-assisted system to extract COVID-19 infected sections from lung CT scans (coronal view). It includes following steps: (i) Threshold filter to extract the lung region by eliminating possible artifacts; (ii) Image enhancement using Harmony-Search-Optimization and Otsu thresholding; (iii) Image segmentation to extract infected region(s); and (iv) Region-of-interest (ROI) extraction (features) from binary image to compute level of severity. The features that are extracted from ROI are then employed to identify the pixel ratio between the lung and infection sections to identify infection level of severity. The primary objective of the tool is to assist the pulmonologist not only to detect but also to help plan treatment process. As a consequence, for mass screening processing, it will help prevent diagnostic burden.
Deep learning for word-level handwritten Indic script identification
Jan 05, 2018

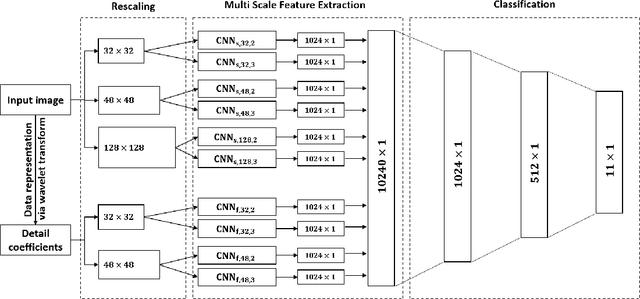
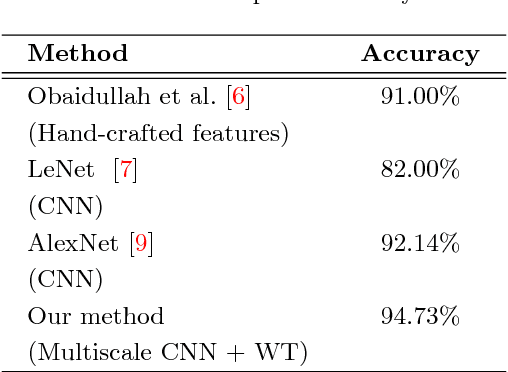
We propose a novel method that uses convolutional neural networks (CNNs) for feature extraction. Not just limited to conventional spatial domain representation, we use multilevel 2D discrete Haar wavelet transform, where image representations are scaled to a variety of different sizes. These are then used to train different CNNs to select features. To be precise, we use 10 different CNNs that select a set of 10240 features, i.e. 1024/CNN. With this, 11 different handwritten scripts are identified, where 1K words per script are used. In our test, we have achieved the maximum script identification rate of 94.73% using multi-layer perceptron (MLP). Our results outperform the state-of-the-art techniques.
Client-Driven Content Extraction Associated with Table
Apr 06, 2013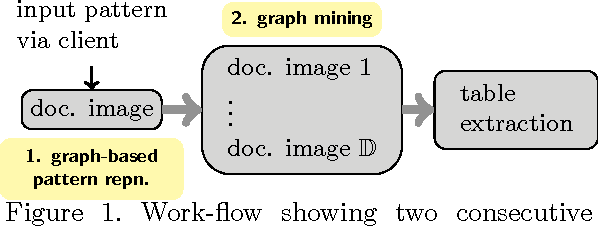
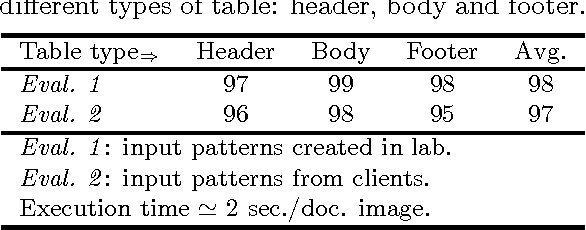
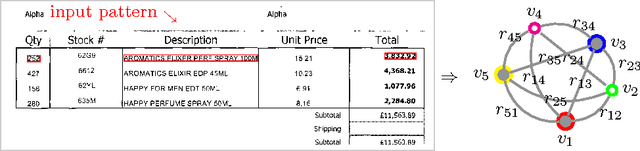

The goal of the project is to extract content within table in document images based on learnt patterns. Real-world users i.e., clients first provide a set of key fields within the table which they think are important. These are first used to represent the graph where nodes are labelled with semantics including other features and edges are attributed with relations. Attributed relational graph (ARG) is then employed to mine similar graphs from a document image. Each mined graph will represent an item within the table, and hence a set of such graphs will compose a table. We have validated the concept by using a real-world industrial problem.
Stroke-Based Cursive Character Recognition
Apr 01, 2013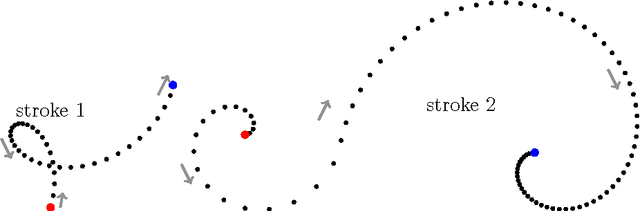

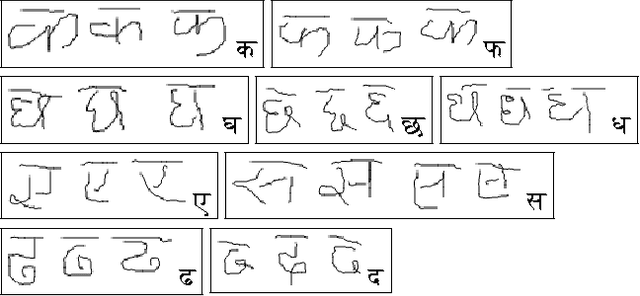
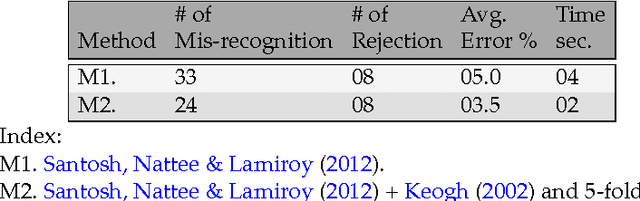
Human eye can see and read what is written or displayed either in natural handwriting or in printed format. The same work in case the machine does is called handwriting recognition. Handwriting recognition can be broken down into two categories: off-line and on-line. ...
Handwritten and Printed Text Separation in Real Document
Mar 19, 2013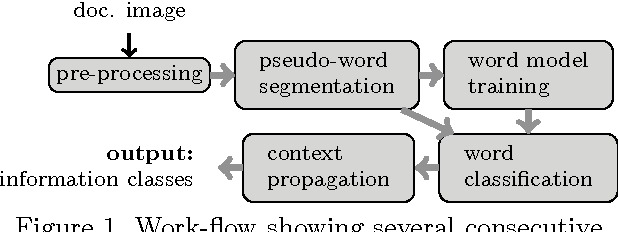
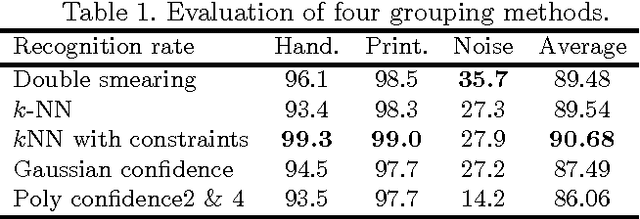


The aim of the paper is to separate handwritten and printed text from a real document embedded with noise, graphics including annotations. Relying on run-length smoothing algorithm (RLSA), the extracted pseudo-lines and pseudo-words are used as basic blocks for classification. To handle this, a multi-class support vector machine (SVM) with Gaussian kernel performs a first labelling of each pseudo-word including the study of local neighbourhood. It then propagates the context between neighbours so that we can correct possible labelling errors. Considering running time complexity issue, we propose linear complexity methods where we use k-NN with constraint. When using a kd-tree, it is almost linearly proportional to the number of pseudo-words. The performance of our system is close to 90%, even when very small learning dataset where samples are basically composed of complex administrative documents.
Statistical Texture Features based Handwritten and Printed Text Classification in South Indian Documents
Mar 13, 2013
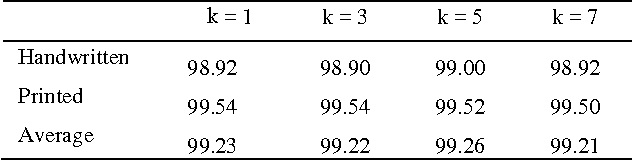


In this paper, we use statistical texture features for handwritten and printed text classification. We primarily aim for word level classification in south Indian scripts. Words are first extracted from the scanned document. For each extracted word, statistical texture features are computed such as mean, standard deviation, smoothness, moment, uniformity, entropy and local range including local entropy. These feature vectors are then used to classify words via k-NN classifier. We have validated the approach over several different datasets. Scripts like Kannada, Telugu, Malayalam and Hindi i.e., Devanagari are primarily employed where an average classification rate of 99.26% is achieved. In addition, to provide an extensibility of the approach, we address Roman script by using publicly available dataset and interesting results are reported.