 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Texture Features based Handwritten and Printed Text Classification in South Indian Documents
Paper and Code
Mar 13, 2013
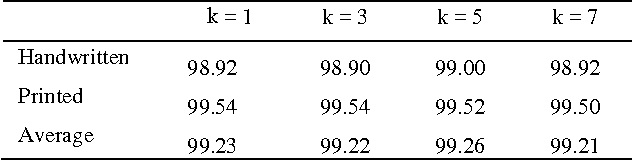


In this paper, we use statistical texture features for handwritten and printed text classification. We primarily aim for word level classification in south Indian scripts. Words are first extracted from the scanned document. For each extracted word, statistical texture features are computed such as mean, standard deviation, smoothness, moment, uniformity, entropy and local range including local entropy. These feature vectors are then used to classify words via k-NN classifier. We have validated the approach over several different datasets. Scripts like Kannada, Telugu, Malayalam and Hindi i.e., Devanagari are primarily employed where an average classification rate of 99.26% is achieved. In addition, to provide an extensibility of the approach, we address Roman script by using publicly available dataset and interesting results are reported.