 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Texture Features based Handwritten and Printed Text Classification in South Indian Documents
Mar 13, 2013
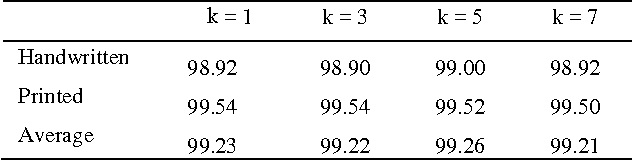


In this paper, we use statistical texture features for handwritten and printed text classification. We primarily aim for word level classification in south Indian scripts. Words are first extracted from the scanned document. For each extracted word, statistical texture features are computed such as mean, standard deviation, smoothness, moment, uniformity, entropy and local range including local entropy. These feature vectors are then used to classify words via k-NN classifier. We have validated the approach over several different datasets. Scripts like Kannada, Telugu, Malayalam and Hindi i.e., Devanagari are primarily employed where an average classification rate of 99.26% is achieved. In addition, to provide an extensibility of the approach, we address Roman script by using publicly available dataset and interesting results are reported.
Gaussian Mixture Model for Handwritten Script Identification
Mar 12, 2013


This paper presents a Gaussian Mixture Model (GMM) to identify the script of handwritten words of Roman, Devanagari, Kannada and Telugu scripts. It emphasizes the significance of directional energies for identification of script of the word. It is robust to varied image sizes and different styles of writing. A GMM is modeled using a set of six novel features derived from directional energy distributions of the underlying image. The standard deviation of directional energy distributions are computed by decomposing an image matrix into right and left diagonals. Furthermore, deviation of horizontal and vertical distributions of energies is also built-in to GMM. A dataset of 400 images out of 800 (200 of each script) are used for training GMM and the remaining is for testing. An exhaustive experimentation is carried out at bi-script, tri-script and multi-script level and achieved script identification accuracies in percentage as 98.7, 98.16 and 96.91 respectively.
Multi-font Multi-size Kannada Numeral Recognition Based on Structural Features
Nov 18, 2011



In this paper a fast and novel method is proposed for multi-font multi-size Kannada numeral recognition which is thinning free and without size normalization approach. The different structural feature are used for numeral recognition namely, directional density of pixels in four directions, water reservoirs, maximum profile distances, and fill hole density are used for the recognition of Kannada numerals. A Euclidian minimum distance criterion is used to find minimum distances and K-nearest neighbor classifier is used to classify the Kannada numerals by varying the size of numeral image from 16 to 50 font sizes for the 20 different font styles from NUDI and BARAHA popular word processing Kannada software. The total 1150 numeral images are tested and the overall accuracy of classification is found to be 100%. The average time taken by this method is 0.1476 seconds.
A Single Euler Number Feature for Multi-font Multi-size Kannada Numeral Recognition
Nov 18, 2011



In this paper a novel approach is proposed based on single Euler number feature which is free from thinning and size normalization for multi-font and multi-size Kannada numeral recognition system. A nearest neighbor classification is used for classification of Kannada numerals by considering the Euclidian distance. A total 1500 numeral images with different font sizes between (10..84) are tested for algorithm efficiency and the overall the classification accuracy is found to be 99.00% .The said method is thinning free, fast, and showed encouraging results on varying font styles and sizes of Kannada numerals.
Spatial Features for Multi-Font/Multi-Size Kannada Numerals and Vowels Recognition
Jul 06, 2011



This paper presents multi-font/multi-size Kannada numerals and vowels recognition based on spatial features. Directional spatial features viz stroke density, stroke length and the number of stokes in an image are employed as potential features to characterize the printed Kannada numerals and vowels. Based on these features 1100 numerals and 1400 vowels are classified with Multi-class Support Vector Machines (SVM). The proposed system achieves the recognition accuracy as 98.45% and 90.64% for numerals and vowels respectively.
Morphological Reconstruction for Word Level Script Identification
Jul 04, 2011



A line of a bilingual document page may contain text words in regional language and numerals in English. For Optical Character Recognition (OCR) of such a document page, it is necessary to identify different script forms before running an individual OCR system. In this paper, we have identified a tool of morphological opening by reconstruction of an image in different directions and regional descriptors for script identification at word level, based on the observation that every text has a distinct visual appearance. The proposed system is developed for three Indian major bilingual documents, Kannada, Telugu and Devnagari containing English numerals. The nearest neighbour and k-nearest neighbour algorithms are applied to classify new word images. The proposed algorithm is tested on 2625 words with various font styles and sizes. The results obtained are quite encouraging
* 11 Pages, 8 Figures,5 Tables; Revised: 15-06-2007,Published: 30-06-2007