 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClient-Driven Content Extraction Associated with Table
Apr 06, 2013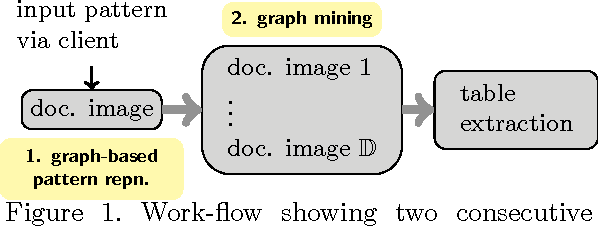
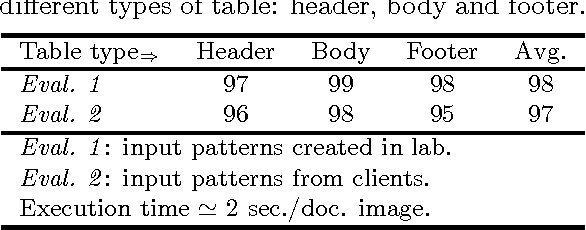
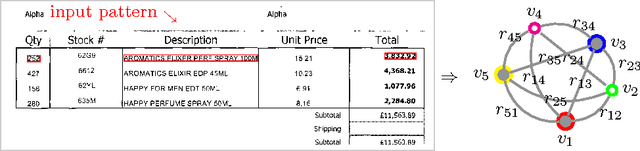

The goal of the project is to extract content within table in document images based on learnt patterns. Real-world users i.e., clients first provide a set of key fields within the table which they think are important. These are first used to represent the graph where nodes are labelled with semantics including other features and edges are attributed with relations. Attributed relational graph (ARG) is then employed to mine similar graphs from a document image. Each mined graph will represent an item within the table, and hence a set of such graphs will compose a table. We have validated the concept by using a real-world industrial problem.
Handwritten and Printed Text Separation in Real Document
Mar 19, 2013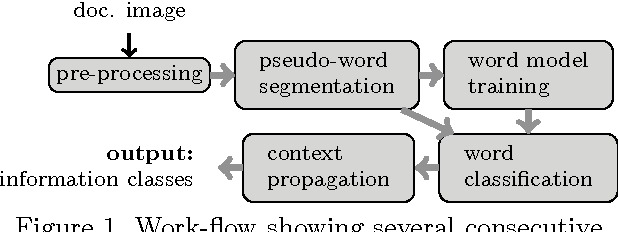
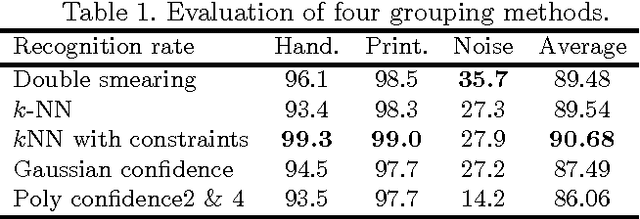


The aim of the paper is to separate handwritten and printed text from a real document embedded with noise, graphics including annotations. Relying on run-length smoothing algorithm (RLSA), the extracted pseudo-lines and pseudo-words are used as basic blocks for classification. To handle this, a multi-class support vector machine (SVM) with Gaussian kernel performs a first labelling of each pseudo-word including the study of local neighbourhood. It then propagates the context between neighbours so that we can correct possible labelling errors. Considering running time complexity issue, we propose linear complexity methods where we use k-NN with constraint. When using a kd-tree, it is almost linearly proportional to the number of pseudo-words. The performance of our system is close to 90%, even when very small learning dataset where samples are basically composed of complex administrative documents.