 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten and Printed Text Separation in Real Document
Paper and Code
Mar 19, 2013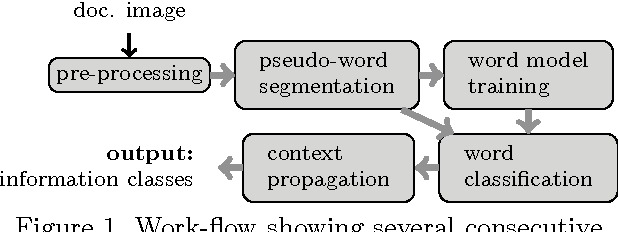
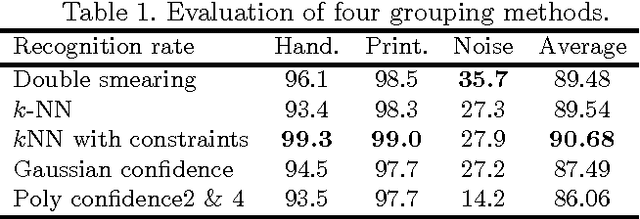


The aim of the paper is to separate handwritten and printed text from a real document embedded with noise, graphics including annotations. Relying on run-length smoothing algorithm (RLSA), the extracted pseudo-lines and pseudo-words are used as basic blocks for classification. To handle this, a multi-class support vector machine (SVM) with Gaussian kernel performs a first labelling of each pseudo-word including the study of local neighbourhood. It then propagates the context between neighbours so that we can correct possible labelling errors. Considering running time complexity issue, we propose linear complexity methods where we use k-NN with constraint. When using a kd-tree, it is almost linearly proportional to the number of pseudo-words. The performance of our system is close to 90%, even when very small learning dataset where samples are basically composed of complex administrative documents.